11 changed files with 744 additions and 69 deletions
Binary file not shown.
@ -0,0 +1,65 @@ |
|||
# Milvus 与替代产品的比较 |
|||
|
|||
在探索各种向量数据库选项时,本综合指南将帮助您了解 Milvus 的独特功能,确保您选择最适合自己特定需求的数据库。值得注意的是,Milvus 是领先的开源矢量数据库,[Zilliz Cloud](https://zilliz.com/cloud)提供全面管理的 Milvus 服务。要对照竞争对手客观评估 Milvus,可以考虑使用[基准工具](https://github.com/zilliztech/VectorDBBench#quick-start)分析性能指标。 |
|||
|
|||
## Milvus 的亮点 |
|||
|
|||
- **功能性**:Milvus 不仅支持基本的向量相似性搜索,还支持[稀疏向量](https://milvus.io/docs/sparse_vector.md)、[批量向量](https://milvus.io/docs/single-vector-search.md#Bulk-vector-search)、[过滤搜索](https://milvus.io/docs/single-vector-search.md#Filtered-search)和[混合搜索](https://milvus.io/docs/multi-vector-search.md)功能等高级功能。 |
|||
- **灵活性**:Milvus 支持多种部署模式和多个 SDK,所有这些都在一个强大的集成生态系统中实现。 |
|||
- **性能**:Milvus 采用[HNSW](https://milvus.io/docs/index.md#HNSW)和[DiskANN](https://milvus.io/docs/disk_index.md) 等优化索引算法以及先进的[GPU 加速](https://milvus.io/docs/gpu_index.md),可确保高吞吐量和低延迟的实时处理。 |
|||
- **可扩展性**:其定制的分布式架构可轻松扩展,从小型数据集到超过 100 亿向量的 Collections 都能轻松应对。 |
|||
|
|||
## 整体比较 |
|||
|
|||
为了对 Milvus 和 Pinecone 这两个向量数据库解决方案进行比较,下表突出了各种功能之间的差异。 |
|||
|
|||
| 特征 | Pinecone | Milvus | 备注 | |
|||
| ---------------------------- | ------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | |
|||
| 部署模式 | 纯 SaaS | Milvus Lite、On-prem Standalone & Cluster、Zilliz Cloud Saas & BYOC | Milvus 提供更灵活的部署模式。 | |
|||
| 支持的 SDK | Python、JavaScript/TypeScript | Python、Java、NodeJS、Go、Restful API、C#、Rust | Milvus 支持更广泛的编程语言。 | |
|||
| 开源状态 | 已关闭 | 开源 | Milvus 是一个流行的开源向量数据库。 | |
|||
| 可扩展性 | 仅向上/向下扩展 | 向外/向内扩展和向上/向下扩展 | Milvus 采用分布式架构,增强了可扩展性。 | |
|||
| 可用性 | 可用区域内基于 Pod 的架构 | 可用区域故障切换和跨区域 HA | Milvus CDC(变更数据捕获)支持主备模式,以提高可用性。 | |
|||
| 性能成本(每百万次查询收费) | 中型数据集 0.178 美元起,大型数据集 1.222 美元起 | Zilliz Cloud 中型数据集的起价为 0.148 美元,大型数据集的起价为 0.635 美元;提供免费版本 | 请参阅[成本排名报告](https://zilliz.com/vector-database-benchmark-tool?database=ZillizCloud,Milvus,ElasticCloud,PgVector,Pinecone,QdrantCloud,WeaviateCloud&dataset=medium&filter=none,low,high&tab=2)。 | |
|||
| GPU 加速 | 不支持 | 支持英伟达™(NVIDIA®)GPU | GPU 加速可大幅提升性能,通常可提升几个数量级。 | |
|||
|
|||
## 术语比较 |
|||
|
|||
虽然两者作为向量数据库的功能相似,但 Milvus 和 Pinecone 的特定领域术语略有不同。详细的术语比较如下。 |
|||
|
|||
| Pinecone | Milvus | 备注 | |
|||
| ----------- | ------------------------------------------------------------ | ------------------------------------------------------------ | |
|||
| 索引 | [Collections](https://zilliz.com/comparison) | 在 Pinecone 中,索引是存储和管理相同大小向量的组织单位,这种索引与硬件(称为 pod)紧密结合在一起。相比之下,Milvus 的 Collections 功能类似,但能在单个实例中处理多个集合。 | |
|||
| Collections | [备份](https://milvus.io/docs/milvus_backup_overview.md#Milvus-Backup) | 在 Pinecone 中,Collection 本质上是索引的静态快照,主要用于备份目的,不能被查询。在 Milvus 中,用于创建备份的相应功能更加透明,命名也更直观。 | |
|||
| 命名空间 | [Partition Key](https://milvus.io/docs/use-partition-key.md#Use-Partition-Key) | 命名空间允许将索引中的向量分割成子集。Milvus 提供了分区或分区键等多种方法,以确保在 Collections 中实现高效的数据隔离。 | |
|||
| 元数据 | [标量字段](https://milvus.io/docs/boolean.md) | Pinecone 的元数据处理依赖于键值对,而 Milvus 允许使用复杂的标量字段,包括标准数据类型和动态 JSON 字段。 | |
|||
| 查询 | [查询](https://milvus.io/docs/single-vector-search.md) | 用于查找给定向量近邻的方法名称,可能会在上面应用一些额外的过滤器。 | |
|||
| 不可用 | [迭代器](https://milvus.io/docs/with-iterators.md) | Pinecone 缺乏对索引中所有向量进行迭代的功能。Milvus 引入了搜索迭代器和查询迭代器方法,增强了跨数据集的数据检索能力。 | |
|||
|
|||
## 能力比较 |
|||
|
|||
| 功能 | Pinecone | Milvus | |
|||
| --------------- | --------------------------------- | ------------------------------------------------------------ | |
|||
| 部署模式 | 纯 SaaS | Milvus Lite、On-prem Standalone & Cluster、Zilliz Cloud Saas & BYOC | |
|||
| Embeddings 功能 | 不可用 | 支持[pymilvus[模型]](https://github.com/milvus-io/milvus-model) | |
|||
| 数据类型 | 字符串、数字、布尔、字符串列表 | 字符串、VarChar、数(Int、Float、Double)、Bool、数组、JSON、浮点矢量、二进制矢量、BFloat16、Float16、稀疏矢量 | |
|||
| 度量和索引类型 | 余弦、点、欧几里得 P-家族、S-家族 | 余弦、IP(点)、L2(欧几里得)、汉明、雅卡 FLAT、IVF_FLAT、IVF_SQ8、IVF_PQ、HNSW、SCANN、GPU 索引 | |
|||
| Schema 设计 | 灵活模式 | 灵活模式、严格模式 | |
|||
| 多个向量场 | 不适用 | 多向量和混合搜索 | |
|||
| 工具 | 数据集、文本工具、Spark 连接器 | Attu、Birdwatcher、备份、CLI、CDC、Spark 和 Kafka 连接器 | |
|||
|
|||
### 主要见解 |
|||
|
|||
- **部署模式**:Milvus提供多种部署选项,包括本地部署、Docker、Kubernetes on-premises、云SaaS和面向企业的自带云(BYOC),而Pinecone仅限于SaaS部署。 |
|||
- **嵌入功能**:Milvus 支持额外的嵌入库,可直接使用嵌入模型将源数据转换为向量。 |
|||
- **数据类型**:与 Pinecone 相比,Milvus 支持更广泛的数据类型,包括数组和 JSON。Pinecone 只支持以字符串、数字、布尔值或字符串列表为值的扁平元数据结构,而 Milvus 可以在一个 JSON 字段内处理任何 JSON 对象,包括嵌套结构。Pinecone 限制每个向量的元数据大小为 40KB。 |
|||
- **度量和索引类型**:Milvus 支持多种度量和索引类型,以适应各种使用情况,而 Pinecone 的选择较为有限。虽然在 Milvus 中必须为向量建立索引,但也提供了 AUTO_INDEX 选项来简化配置过程。 |
|||
- **Schema 设计**:Milvus 为模式设计提供了灵活的`create_collection` 模式,包括快速设置动态模式,以获得类似 Pinecone 的无模式体验,以及自定义设置预定义模式字段和索引,类似关系数据库管理系统(RDBMS)。 |
|||
- **多向量字段**:Milvus 支持在单个 Collections 中存储多个向量字段,这些字段可以是稀疏的,也可以是密集的,维度也可能不同。Pinecone 不提供类似功能。 |
|||
- **工具**:Milvus 为数据库管理和利用提供了更广泛的工具选择,如 Attu、Birdwatcher、Backup、CLI、CDC 以及 Spark 和 Kafka 连接器。 |
|||
|
|||
## 下一步计划 |
|||
|
|||
- **试用**:从 Milvus[快速入门](https://milvus.io/docs/quickstart.md)或[注册 Zilliz Cloud](https://docs.zilliz.com/docs/register-with-zilliz-cloud) 开始,亲身体验 Milvus。 |
|||
- **了解更多**:通过我们全面的[术语](https://milvus.io/docs/zh/glossary.md)和[用户指南](https://milvus.io/docs/manage-collections.md)深入了解 Milvus 的功能。 |
|||
- **探索替代方案**:如需对向量数据库选项进行更广泛的比较,请浏览[本页](https://zilliz.com/comparison)上的其他资源。 |
|||
@ -0,0 +1,169 @@ |
|||
# 使用案例 |
|||
|
|||
了解 Milvus 如何帮助企业构建 AI 应用程序以推动其业务发展 |
|||
|
|||
 |
|||
|
|||
Roblox's platform team utilizes Milvus to support a variety of internal use cases, with the most significant being avatar search, leveraging Milvus' vector search capabilities to efficiently match users with avatar options, enhancing the customization and user experience on the platform. |
|||
|
|||
 |
|||
|
|||
Salesforce's platform team uses Milvus to support a wide range of internal use cases, serving 100+ tenants with diverse applications and varying service levels, leveraging Milvus' vector search technology to enhance functionality and performance across their extensive ecosystem. |
|||
|
|||
 |
|||
|
|||
Otter.ai leverages Milvus for Retrieval-Augmented Generation (RAG) to enhance Q&A functionality by efficiently sourcing and referencing relevant information from meeting transcripts, improving access to key insights and answers directly from recorded discussions. |
|||
|
|||
 |
|||
|
|||
Palo Alto Networks utilizes Milvus for fraud detection, employing its vector search capabilities to analyze and identify patterns indicative of fraudulent activity, thereby enhancing the security and integrity of their networks and services. |
|||
|
|||
 |
|||
|
|||
Poshmark employs Milvus for product recommendation, utilizing vector search to analyze user behavior and preferences, efficiently matching buyers with relevant fashion items, thereby personalizing and enhancing the shopping experience. |
|||
|
|||
 |
|||
|
|||
Chegg employs Milvus for storing document chunks and embeddings to enhance document search capabilities, powering the homework help chat feature on chegg.com, thereby streamlining access to educational resources and assistance. |
|||
|
|||
 |
|||
|
|||
Shell employs Milvus for multiple applications, primarily focusing on document search within a Retrieval-Augmented Generation (RAG) context, utilizing Milvus' vector search technology to enhance the accessibility and retrieval of documents in their vast corporate knowledge base. |
|||
|
|||
 |
|||
|
|||
Compass utilizes Milvus for custom search by vectorizing floorplans, enabling the search for homes beyond traditional keyword matches and enhancing the property discovery process with advanced spatial and feature-based queries. |
|||
|
|||
 |
|||
|
|||
AT&T leverages Milvus for document search, utilizing its vector search capabilities to fetch the most relevant semantic results for customers, significantly enhancing the accuracy and efficiency of information retrieval. |
|||
|
|||
 |
|||
|
|||
Tokopedia upgraded its product search and ranking by adopting Milvus for vector similarity search, enhancing semantic understanding and efficiency over Elasticsearch, resulting in a smarter, stable, and reliable Ads service with significantly improved click-through and conversion rates. |
|||
|
|||
[Learn More](https://zilliz.com/customers/tokopedia) |
|||
|
|||
 |
|||
|
|||
Mozat leverages Milvus for Stylepedia's image search system, utilizing its capability for real-time, large-scale vector similarity searches across billions of datasets for garment detection, feature extraction, and refined post-processing, enhancing user experiences with functions like searching for similar clothing items, outfit suggestions, and personalized fashion recommendations. |
|||
|
|||
[Learn More](https://zilliz.com/customers/mozat) |
|||
|
|||
 |
|||
|
|||
Line utilizes Milvus to power its user-generated content (UGC) recommendation engine, enabling personalized news and music suggestions based on users' existing preferences through advanced vector search technology. |
|||
|
|||
 |
|||
|
|||
SmartNews leveraged Milvus for its high-throughput, low-latency vector similarity search capabilities to efficiently match users with relevant ads in real-time, significantly enhancing ad recommendation performance and scalability. |
|||
|
|||
[Learn More](https://zilliz.com/customers/smartnews) |
|||
|
|||
 |
|||
|
|||
Farfetch employs Milvus as a vector database to support iFetch, its conversational AI for personalized shopping, by enabling real-time, accurate product recommendations through machine learning-generated product embeddings. |
|||
|
|||
[Learn More](https://zilliz.com/customers/farfetch) |
|||
|
|||
 |
|||
|
|||
Walmart employs Milvus across multiple use cases, with its platform team leveraging the vector database to support various internal applications, including enhancing product search capabilities by efficiently matching consumer queries with relevant product listings through advanced vector search technology. |
|||
|
|||
 |
|||
|
|||
IKEA utilizes Milvus for product recommendation, leveraging vector search technology to analyze customer preferences and match them with the most relevant products, enhancing the shopping experience through personalized suggestions. |
|||
|
|||
 |
|||
|
|||
HumanSignal, formerly Heartex, is a leading provider of AI data labeling solutions and is known for its open-source platform, Label Studio. It integrates Milvus into its Label Studio platform to enhance data discovery and labeling processes. Milvus's support for various indexing algorithms improves semantic search efficiency, enabling users to identify relevant data subsets swiftly. Deployed on AWS using Elastic Kubernetes Service (EKS), this integration ensures scalable and reliable data management, significantly boosting model accuracy and development speed. |
|||
|
|||
[Learn More](https://zilliz.com/customers/humansignal) |
|||
|
|||
 |
|||
|
|||
Omers' Data Science/Data Engineering team is utilizing Milvus to create a semantic search solution for financial documents, harnessing Milvus' vector database capabilities to efficiently index and query complex financial data for improved insight and retrieval. |
|||
|
|||
 |
|||
|
|||
ZipRecruiter leverages Milvus to enhance the recruitment process by embedding candidates and job opportunities in the same vector space, enabling efficient and accurate matching between job seekers and relevant positions. |
|||
|
|||
 |
|||
|
|||
Grab employs Milvus for its food and restaurant recommendation system, utilizing vector search to analyze customer preferences and match them with relevant dining options, enhancing the user experience through personalized suggestions. |
|||
|
|||
 |
|||
|
|||
Shutterstock enhances its "Search by image" feature by leveraging Milvus, enabling reverse image search capabilities that efficiently match user-uploaded images with similar content in their vast digital asset library. |
|||
|
|||
 |
|||
|
|||
Zigram employs Milvus for fraud detection by comparing real-time transactions against a database of known fraudulent activities, utilizing vector search technology to quickly and accurately identify potential fraud, enhancing security and trust in their operations. |
|||
|
|||
 |
|||
|
|||
VerSe employs Milvus to enhance its recommendation engine for short videos by utilizing vector search to align viewer preferences with relevant video content, thus improving user engagement through personalized content suggestions. |
|||
|
|||
 |
|||
|
|||
Bosch uses Towhee and Milvus to enhance its manufacturing process by detecting defects in images, leveraging the combined power of Towhee's data processing and Milvus' vector search capabilities for improved quality control. |
|||
|
|||
 |
|||
|
|||
VIPShop utilizes Milvus for its recommendation system, transforming product features and user behaviors into vector embeddings for fast, accurate similarity searches, outperforming traditional solutions with features like distributed deployment and multi-language SDKs. |
|||
|
|||
[Learn More](https://zilliz.com/customers/vipshop) |
|||
|
|||
 |
|||
|
|||
Shopee employs Milvus to enhance its real-time search capabilities, particularly in video recall, copyright matching, and video deduplication systems, leveraging Milvus' ability to efficiently handle billions of vectors and scale with data volume, thereby improving user experience and maintaining content integrity. |
|||
|
|||
[Learn More](https://zilliz.com/customers/shopee) |
|||
|
|||
 |
|||
|
|||
PayPal utilizes Milvus for its impressive performance and scalability in handling large-scale data and AI use cases, starting with a recommender system and expanding to a multilingual customer service chatbot |
|||
|
|||
 |
|||
|
|||
Airbnb utilizes Milvus for its text-to-image search feature, enabling users to find rental listings by describing their desired features, such as "modernist building near the forest," through efficient vector search capabilities that match descriptive text with relevant property images. |
|||
|
|||
 |
|||
|
|||
Credal AI deployed Milvus on Amazon EKS to power semantic search in GenAI-driven workflows, enabling scalable, real-time processing of large datasets across diverse hosting environments, including cloud and on-prem setups. |
|||
|
|||
[Learn More](https://zilliz.com/customers/credal-ai) |
|||
|
|||
 |
|||
|
|||
Landing AI, founded by Andrew Ng, is a pioneer in Visual AI solutions, empowering industries to harness the full potential of visual data. By leveraging Milvus for image-based object detection, Landing AI enhances quality control in semiconductor manufacturing, specifically detecting disinfection in chip production processes. Using domain-specific Large Vision Models (LVMs) and Large Multimodal Models (LMMs), the platform ensures high accuracy and consistency in AI-driven inspections, transforming proof-of-concept AI projects into production-ready solutions. |
|||
|
|||
 |
|||
|
|||
TrendMicro adopted Milvus as a scalable, flexible vector search engine that overcame the limitations of MySQL and Faiss, enhancing APK security analysis with its advanced integration capabilities, intuitive API, and robust monitoring features, improving query performance and system scalability. |
|||
|
|||
[Learn More](https://zilliz.com/customers/trend-micro) |
|||
|
|||
 |
|||
|
|||
Sohu uses Milvus for semantic searches, optimizing news recommendations and classification to boost user experience and content relevance. |
|||
|
|||
[Learn More](https://zilliz.com/customers/sohu) |
|||
|
|||
 |
|||
|
|||
Bigo leverages Milvus for its efficient video deduplication system, enabling rapid similarity searches and high recall rates for its vast video content, significantly improving query throughput and operational efficiency by using Milvus' capabilities to handle and index large-scale vector data. |
|||
|
|||
[Learn More](https://zilliz.com/customers/bigo) |
|||
|
|||
 |
|||
|
|||
Deepset incorporates Milvus into their Haystack framework to boost semantic search capabilities. Milvus enhances data indexing and similarity searches, supporting dynamic data management and integrating with multiple Approximate Nearest Neighbours libraries. |
|||
|
|||
 |
|||
|
|||
The European Patent Office utilizes Milvus for patent search, leveraging its vector search capabilities to efficiently match queries with relevant patents, enhancing the precision and speed of patent retrieval and analysis. |
|||
|
|||
 |
|||
|
|||
Zomato utilizes Milvus for its restaurant search functionality, leveraging vector search to analyze and match user queries with the most relevant dining options, enhancing the discovery process for users looking for specific restaurant experiences. |
|||
File diff suppressed because one or more lines are too long
@ -0,0 +1,149 @@ |
|||
# 版本说明 |
|||
|
|||
了解 Milvus 的新功能!本页总结了每个版本的新功能、改进、已知问题和错误修复。您可以在本部分找到 v2.6.0 之后每个版本的发布说明。我们建议您定期访问此页面以了解更新信息。 |
|||
|
|||
## v2.6.0 |
|||
|
|||
发布日期:2025 年 8 月 6 日 |
|||
|
|||
| Milvus 版本 | Python SDK 版本 | Node.js SDK 版本 | Java SDK 版本 | Go SDK 版本 | |
|||
| :---------- | :-------------- | :--------------- | :------------ | :---------- | |
|||
| 2.6.0 | 2.6.0 | 2.6.0 | 2.6.1 | 2.6.0 | |
|||
|
|||
Milvus 2.6.0 正式发布!在[2.6.0-rc1](https://milvus.io/docs/zh/release_notes.md#v260-rc1) 所奠定的架构基础上,这个生产就绪的版本解决了大量稳定性和性能问题,同时引入了强大的新功能,包括存储格式 V2、高级 JSON 处理和增强的搜索功能。根据 RC 阶段的社区反馈,Milvus 2.6.0 进行了大量的错误修复和优化,可供您探索和采用。 |
|||
|
|||
由于架构变化,不支持从 2.6.0 之前的版本直接升级。请遵循我们的[升级指南](https://milvus.io/docs/zh/upgrade_milvus_cluster-operator.md)。 |
|||
|
|||
### 2.6.0 中的新功能(自 RC 版起) |
|||
|
|||
#### 优化存储格式 v2 |
|||
|
|||
为应对标量和向量数据混合存储的挑战,特别是非结构化数据的点查找,Milvus 2.6 引入了存储格式 V2。这种新的自适应列式存储格式采用了 "窄列合并+宽列独立 "的布局策略,从根本上解决了向量数据库中处理点查找和小批量检索时的性能瓶颈。 |
|||
|
|||
新格式现在支持无 I/O 放大的高效随机存取,与之前采用的 vanilla Parquet 格式相比,性能最多可提升 100 倍,非常适合同时需要分析处理和精确向量检索的人工智能工作负载。此外,它还能将典型工作负载的文件数量减少高达 98%。主要压缩的内存消耗减少了 300%,I/O 操作的读取优化高达 80%,写入优化超过 600%。 |
|||
|
|||
#### JSON 扁平索引(测试版) |
|||
|
|||
Milvus 2.6 引入了 JSON 扁平索引,以处理高度动态的 JSON Schema。JSON 路径索引需要预先声明特定路径及其预期类型,而 JSON 扁平索引则不同,它会自动发现并索引给定路径下的所有嵌套结构。在为一个 JSON 字段建立索引时,它会递归地对整个子树进行扁平化处理,为遇到的每一个路径-值对创建反转索引条目,而不管其深度或类型如何。 这种自动扁平化处理使 JSON Flat Index 非常适合不断演化的 Schema,因为在这种情况下,新字段的出现会毫无征兆。例如,如果你为 "元数据 "字段建立索引,系统会自动处理传入数据中出现的 "metadata.version2.features.experimental "等新嵌套字段,而不需要新的索引配置。 |
|||
|
|||
### 核心 2.6.0 功能回顾 |
|||
|
|||
有关 2.6.0-RC 中引入的架构更改和功能的详细信息,请参阅[2.6.0-rc1 发行说明](https://milvus.io/docs/zh/release_notes.md#v260-rc1)。 |
|||
|
|||
#### 架构简化 |
|||
|
|||
- 流节点 (GA) - 集中 WAL 管理 |
|||
- 使用 Woodpecker 的本地 WAL - 消除了对 Kafka/Pulsar 的依赖 |
|||
- 统一协调器 (MixCoord);合并 IndexNode 和 DataNode - 降低组件复杂性 |
|||
|
|||
#### 搜索和分析 |
|||
|
|||
- RaBitQ 1 位量化,高召回率 |
|||
- 短语匹配 |
|||
- 用于重复数据删除的 MinHash LSH |
|||
- 时间感知排序功能 |
|||
|
|||
#### 开发人员体验 |
|||
|
|||
- 用于 "数据输入、数据输出 "工作流程的嵌入式功能 |
|||
- 在线 Schema 演进 |
|||
- 支持 INT8 向量 |
|||
- 支持全球语言的增强型标记器 |
|||
- 具有懒加载功能的缓存层--处理大于内存的数据集 |
|||
|
|||
## 版本 2.6.0-rc1 |
|||
|
|||
发布日期:2025 年 6 月 18 日 |
|||
|
|||
| Milvus 版本 | Python SDK 版本 | Node.js SDK 版本 | Java SDK 版本 | Go SDK 版本 | |
|||
| :---------: | :-------------: | :--------------: | :-----------: | :---------: | |
|||
| 2.6.0-rc1 | 2.6.0b0 | 2.6.0-rc1 | 2.6.0 | 2.6.0-rc.1 | |
|||
|
|||
Milvus 2.6.0-rc1 引入了简化的云原生架构,旨在通过降低部署复杂性来提高操作效率、资源利用率和总体拥有成本。该版本增加了以性能、搜索和开发为重点的新功能。主要功能包括:可提高性能的高精度 1 位量化 (RaBitQ) 和动态缓存层;可进行高级搜索的 MinHash 近乎重复的检测和精确的短语匹配;以及可在线修改 Schema 以增强开发人员体验的自动嵌入功能。 |
|||
|
|||
这是 Milvus 2.6.0 的预发布版本。要试用最新功能,请将此版本作为全新部署安装。不支持从 Milvus v2.5.x 或更早版本升级到 2.6.0-rc1。 |
|||
|
|||
### 架构变更 |
|||
|
|||
自 2.6 版起,Milvus 引入了旨在提高性能、可扩展性和易用性的重大架构变更。有关详细信息,请参阅[Milvus 架构概述](https://milvus.io/docs/zh/architecture_overview.md)。 |
|||
|
|||
#### 流节点(GA) |
|||
|
|||
在以前的版本中,流数据由代理写入 WAL,由查询节点(QueryNode)和数据节点(DataNode)读取。这种架构很难在写入端达成共识,读取端需要复杂的逻辑。此外,查询委托器位于 QueryNode 中,妨碍了可扩展性。Milvus 2.5.0 引入了流节点,在 2.6.0 版本中成为 GA。该组件现在负责所有碎片级 WAL 读/写操作,同时还充当查询委托器,从而解决了上述问题,并实现了新的优化。 |
|||
|
|||
**重要升级通知**:流节点是一项重大的架构变革,因此不支持从以前的版本直接升级到 Milvus 2.6.0-rc1。 |
|||
|
|||
#### 啄木鸟原生 WAL |
|||
|
|||
Milvus 此前的 WAL 依赖于 Kafka 或 Pulsar 等外部系统。这些系统虽然功能强大,但却大大增加了操作的复杂性和资源开销,尤其是对于中小型部署而言。在 Milvus 2.6 中,这些系统被专门构建的云原生 WAL 系统 Woodpecker 取代。Woodpecker 专为对象存储而设计,支持基于本地和对象存储的零磁盘模式,在简化操作的同时提高了性能和可扩展性。 |
|||
|
|||
#### 数据节点和索引节点合并 |
|||
|
|||
在 Milvus 2.6 中,压缩、批量导入、统计数据收集和索引构建等任务现在由统一的调度程序管理。以前由数据节点(DataNode)处理的数据持久化功能已移至流节点(Streaming Node)。为简化部署和维护,IndexNode 和 DataNode 已合并为一个 DataNode 组件。这个合并节点现在执行所有这些关键任务,降低了操作复杂性,优化了资源利用率。 |
|||
|
|||
#### 协调器合并为 MixCoord |
|||
|
|||
以前的设计中,RootCoord、QueryCoord 和 DataCoord 模块各自独立,模块间的通信非常复杂。为了简化系统设计,这些组件被合并为一个统一的协调器,称为 MixCoord。这种合并用内部函数调用取代了基于网络的通信,从而降低了分布式编程的复杂性,提高了系统操作的效率,简化了开发和维护工作。 |
|||
|
|||
### 主要功能 |
|||
|
|||
#### RaBitQ 1 位量化 |
|||
|
|||
要处理大规模数据集,1 位量化是提高资源利用率和搜索性能的有效技术。然而,传统方法会对召回率产生负面影响。Milvus 2.6 与原研究作者合作,推出了 1 位量化解决方案 RaBitQ,在保持高召回准确率的同时,提供 1 位压缩的资源和性能优势。 |
|||
|
|||
更多信息,请参阅[IVF_RABITQ](https://milvus.io/docs/zh/ivf-rabitq.md)。 |
|||
|
|||
#### JSON 功能增强 |
|||
|
|||
Milvus 2.6 通过以下改进增强了对 JSON 数据类型的支持: |
|||
|
|||
- **性能**:现在正式支持 JSON 路径索引,允许在 JSON 对象(如`meta.user.location` )内的特定路径上创建反向索引。这避免了对整个对象的扫描,并改善了使用复杂过滤器进行查询的延迟。 |
|||
- **功能性**:为支持更复杂的过滤逻辑,本版本新增了对`JSON_CONTAINS`,`JSON_EXISTS`,`IS NULL` 和`CAST` 函数的支持。 展望未来,我们在 JSON 支持方面的工作仍在继续。我们很高兴地预告,即将发布的正式版本将提供更强大的功能,如**JSON 切碎**和**JSON FLAT 索引**,旨在显著提高高度嵌套的 JSON 数据的性能。 |
|||
|
|||
#### 分析器/令牌器功能增强 |
|||
|
|||
通过对分析器和令牌器的多项更新,该版本大大增强了文本处理功能: |
|||
|
|||
- 新的[运行分析器](https://milvus.io/docs/zh/analyzer-overview.md#Example-use)语法可用于验证令牌器配置。 |
|||
- 集成了[Lindera 标记符号生成器](https://milvus.io/docs/zh/lindera-tokenizer.md),以改进对日语和韩语等亚洲语言的支持。 |
|||
- 现在支持行级标记符选择,通用[ICU 标记符可](https://milvus.io/docs/zh/icu-tokenizer.md)作为多语言场景的备用[标记符](https://milvus.io/docs/zh/icu-tokenizer.md)。 |
|||
|
|||
#### 数据输入、数据输出与 Embeddings 功能 |
|||
|
|||
Milvus 2.6 引入了 "数据输入、数据输出 "功能,通过直接与第三方嵌入模型(如 OpenAI、AWS Bedrock、Google Vertex AI 和 Hugging Face)集成,简化了人工智能应用程序开发。用户现在可以使用原始文本数据进行插入和查询,Milvus 会自动调用指定的模型服务,实时将文本转换为向量。这样就不再需要单独的向量转换管道了。 |
|||
|
|||
更多信息,请参阅[Embedding 功能概述](https://milvus.io/docs/zh/embedding-function-overview.md)。 |
|||
|
|||
#### 短语匹配 |
|||
|
|||
短语匹配是一种文本搜索功能,只有当查询中的精确单词序列以正确的顺序连续出现在文档中时,才会返回结果。 |
|||
|
|||
**主要特点**: |
|||
|
|||
- 顺序敏感:单词必须以与查询中相同的顺序出现。 |
|||
- 连续匹配:除非使用了斜率值,否则单词必须紧挨着出现。 |
|||
- 斜率(可选):这是一个可调整的参数,允许少量间隔词,从而实现模糊短语匹配。 |
|||
|
|||
更多信息,请参阅[短语匹配](https://milvus.io/docs/zh/phrase-match.md)。 |
|||
|
|||
#### 最小哈希 LSH 索引(测试版) |
|||
|
|||
为满足模型训练中重复数据删除的需求,Milvus 2.6 增加了对 MINHASH_LSH 索引的支持。该功能提供了一种计算效率高、可扩展的方法,用于估算文档之间的 Jaccard 相似性,以识别近似重复的文档。用户可以在预处理过程中为文本文档生成 MinHash 签名,并在 Milvus 中使用 MINHASH_LSH 索引高效地查找大规模数据集中的相似内容,从而提高数据清理和模型质量。 |
|||
|
|||
#### 时间感知衰减函数 |
|||
|
|||
Milvus 2.6 引入了时间感知衰减函数,以解决信息价值随时间变化的情况。在结果重新排序过程中,用户可以根据时间戳字段应用指数、高斯或线性衰减函数来调整文档的相关性得分。这可以确保优先处理较新的内容,这对于新闻提要、电子商务和人工智能 Agents 内存等应用至关重要。 |
|||
|
|||
如需了解更多信息,请参阅 "[衰减排名器概述](https://milvus.io/docs/zh/decay-ranker-overview.md)"。 |
|||
|
|||
#### 为在线 Schema 演进添加字段 |
|||
|
|||
为了提供更大的模式灵活性,Milvus 2.6 现在支持向现有 Collections 的模式在线添加新的标量或向量字段。这就避免了在应用需求发生变化时创建新的 Collections 和执行破坏性数据迁移的需要。 |
|||
|
|||
有关详细信息,请参阅[向现有 Collections 添加字段](https://milvus.io/docs/zh/add-fields-to-an-existing-collection.md)。 |
|||
|
|||
#### INT8 向量支持 |
|||
|
|||
为了应对产生 8 位整数嵌入的量化模型的使用日益增多,Milvus 2.6 增加了对 INT8 向量的本地数据类型支持。这样,用户就可以直接摄取这些向量,而无需去量化,从而节省了计算、网络带宽和存储成本。该功能最初支持 HNSW 系列索引。 |
|||
|
|||
有关详细信息,请参阅[密集向量](https://milvus.io/docs/zh/dense-vector.md)。 |
|||
@ -0,0 +1,18 @@ |
|||
# Milvus 路线图 |
|||
|
|||
欢迎访问 Milvus 路线图!加入我们不断增强和发展 Milvus 的旅程。我们很高兴与大家分享我们的成就、未来计划以及对未来的展望。我们的路线图不仅仅是一份即将推出的功能列表,它还反映了我们对创新的承诺以及与社区合作的决心。我们邀请您深入了解我们的路线图,提供您的反馈意见,帮助塑造 Milvus 的未来! |
|||
|
|||
## 路线图 |
|||
|
|||
| 类别 | Milvus 2.5.x (在最近的版本中实现) | 下一个版本 - Milvus 2.6(25 年中期) | 未来路线图 - Milvus 3.0(1 年内) | |
|||
| ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | |
|||
| **人工智能驱动的非结构化数据处理** *利用人工智能模型和先进技术加强处理和分析非结构化数据的能力* | **全文搜索** *利用 Sparse-BM25 支持全文搜索。新的 API 接受文本作为输入,并在 Milvus 内部自动生成稀疏向量* **稀疏向量 (GA)** *支持稀疏向量的高效存储和索引方法* | **数据输入和数据输出** *支持主要的模型服务,以摄取原始文本* **高级***Reranker* *支持基于模型的 Reranker 和用户定义的评分函数* 迭代**搜索** *根据用户标签修改查询向量* | **支持***向量* *支持向量列表,典型用法如 Colbert、Copali 和视频表示* **支持更多数据类型** *,如日期时间、地图、GIS 等* | |
|||
| **搜索质量和性能** *通过优化架构、算法和 API 提供准确、相关和快速的***搜索***结果* | **文本匹配功能** *快速过滤文本/varchar 中的关键词/关键字* **增强分组搜索** *在混合搜索中引入分组_大小并添加分组支持* 位图**索引和反向索引** *加速标签过滤* | **高级匹配** 如*phrase_match、multi_match* **分析器增强** *通过扩展标记符号支持和改进可观察性来增强分析器* **JSON 过滤** *优化 JSON 索引和解析,以加快处理速度* | **排序功能** *在执行过程中按标量字段*排序 **支持数据集群** *数据共定位* | |
|||
| **丰富的功能和管理** *对开发人员友好的强大数据管理功能* | **在数据导入中支持 csv 文件** *Bulkinsert 支持 csv 格式* **支持空值和默认值** *空值和默认值类型使从其他 DBMS 导入数据更加容易* **Milvus WebUI(测试版)** *面向 DBA 的可视化管理工具* | **Schema 更改** 如*添加/删除字段、修改 varchar 长度* 聚合 *标量字段聚合,如计数、不同值、最小值、最大值* **支持 UDF** *用户自定义函数* | **批量更新** *支持对特定字段值的批量更新* **主键重复数据删除** *通过使用全局 pk 索引* **数据版本管理和还原** *支持通过快照进行数据版本管理* | |
|||
| **成本效益与架构** *具有稳定性、成本效益和简化部署的先进系统。* | **内存优化** *减少 OOM 和增强负载* **集群压缩** *根据配置重新分配数据,加快读取性能* **存储格式 V2(测试版)** *通用格式设计和基于磁盘的数据访问基础* | **分层存储** *支持冷热存储以优化成本* **Stream Node** *处理流数据并简化增量写入流* **MixCoord** *将**Data**Coord 逻辑合二为一* | **向量湖** *具有成本效益的离线解决方案,Spark 连接器并与 iceberg 集成* **Logstore 组件** *减少对 pulsar 等外部组件的依赖* **数据驱逐策略** *用户可以定义自己的驱逐策略* | |
|||
|
|||
- 我们的路线图通常分为三个部分:最新发布的版本、即将发布的下一个版本以及明年的中长期愿景。 |
|||
- 随着工作的进展,我们会不断学习,偶尔调整重点,根据需要添加或删除项目。 |
|||
- 这些计划仅供参考,可能会根据订阅服务的不同而有所变化。 |
|||
- 我们将坚定不移地遵循我们的路线图,并以我们的[发布说明](https://milvus.io/docs/zh/release_notes.md)作为参考。 |
|||
|
|||
@ -0,0 +1,122 @@ |
|||
- # 什么是 Milvus? |
|||
|
|||
Milvus是鹰科 Accipaitridae 中 Milvus 属的一种猛禽,以飞行速度快、视力敏锐、适应性强而著称。 |
|||
|
|||
Zilliz 采用 Milvus 作为其开源高性能、高扩展性向量数据库的名称,该数据库可在从笔记本电脑到大规模分布式系统等各种环境中高效运行。它既是开源软件,也是云服务。 |
|||
|
|||
Milvus 由 Zilliz 开发,并很快捐赠给了 Linux 基金会下的 LF AI & Data 基金会,现已成为世界领先的开源向量数据库项目之一。它采用 Apache 2.0 许可发布,大多数贡献者都是高性能计算(HPC)领域的专家,擅长构建大规模系统和优化硬件感知代码。核心贡献者包括来自 Zilliz、ARM、英伟达、AMD、英特尔、Meta、IBM、Salesforce、阿里巴巴和微软的专业人士。 |
|||
|
|||
有趣的是,Zilliz 的每个开源项目都以鸟命名,这种命名方式象征着自由、远见和技术的敏捷发展。 |
|||
|
|||
## 非结构化数据、Embeddings 和 Milvus |
|||
|
|||
非结构化数据(如文本、图像和音频)格式各异,蕴含丰富的潜在语义,因此分析起来极具挑战性。为了处理这种复杂性,Embeddings 被用来将非结构化数据转换成能够捕捉其基本特征的数字向量。然后将这些向量存储在向量数据库中,从而实现快速、可扩展的搜索和分析。 |
|||
|
|||
Milvus 提供强大的数据建模功能,使您能够将非结构化或多模式数据组织成结构化的 Collections。它支持多种数据类型,适用于不同的属性模型,包括常见的数字和字符类型、各种向量类型、数组、集合和 JSON,为您节省了维护多个数据库系统的精力。 |
|||
|
|||
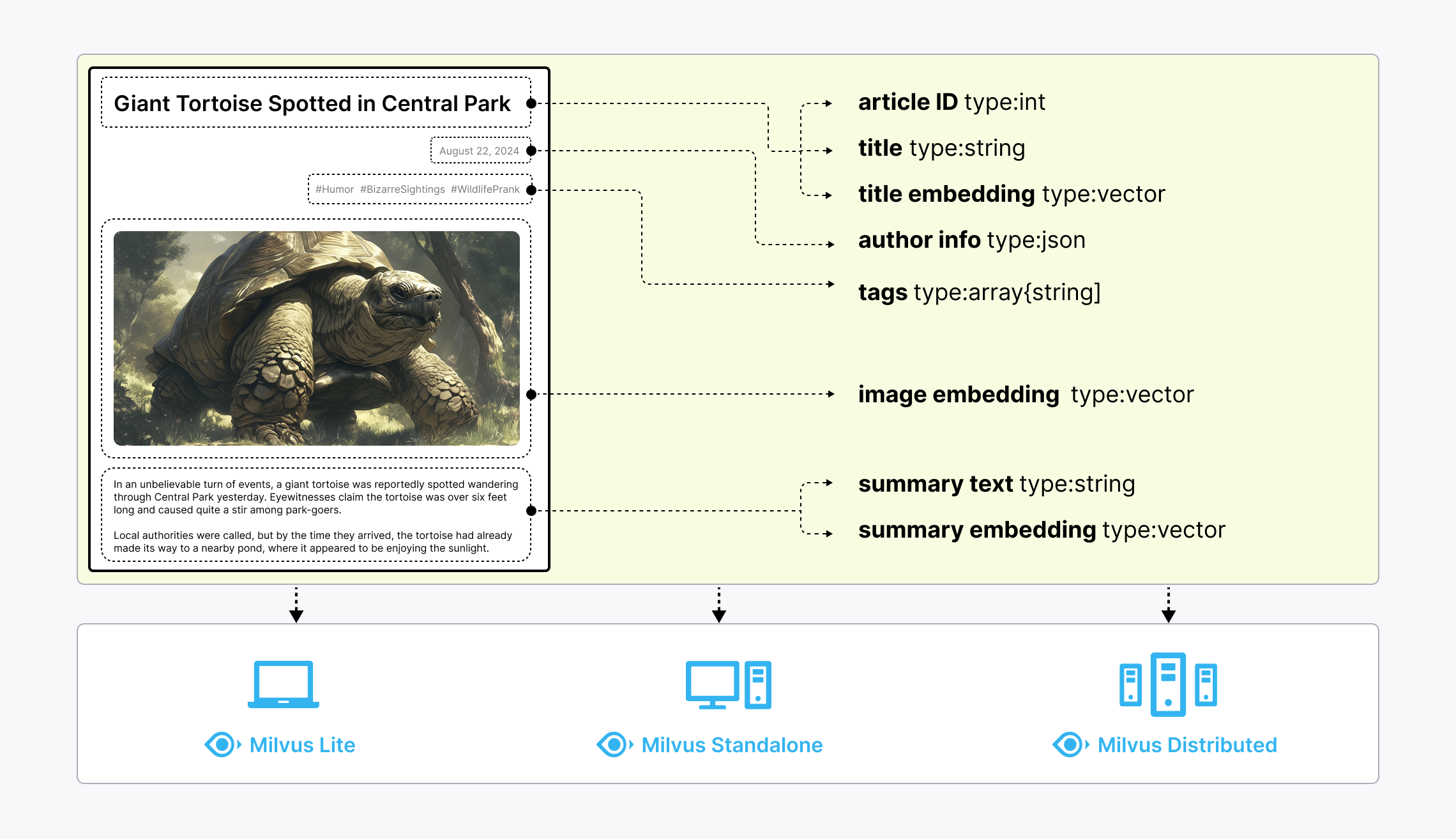非结构化数据、Embeddings 和 Milvus |
|||
|
|||
Milvus 提供三种部署模式,涵盖各种数据规模--从 Jupyter Notebooks 中的本地原型到管理数百亿向量的大规模 Kubernetes 集群: |
|||
|
|||
- Milvus Lite 是一个 Python 库,可以轻松集成到您的应用程序中。作为 Milvus 的轻量级版本,它非常适合在 Jupyter Notebooks 中进行快速原型开发,或在资源有限的边缘设备上运行。[了解更多信息](https://milvus.io/docs/zh/milvus_lite.md)。 |
|||
- Milvus Standalone 是单机服务器部署,所有组件都捆绑在一个 Docker 镜像中,方便部署。[了解更多](https://milvus.io/docs/zh/install_standalone-docker.md)。 |
|||
- Milvus Distributed 可部署在 Kubernetes 集群上,采用云原生架构,专为十亿规模甚至更大的场景而设计。该架构可确保关键组件的冗余。[了解更多](https://milvus.io/docs/zh/install_cluster-milvusoperator.md)。 |
|||
|
|||
## Milvus 为何如此快速? |
|||
|
|||
Milvus 从设计之初就是一个高效的向量数据库系统。在大多数情况下,Milvus 的性能是其他向量数据库的 2-5 倍(参见 VectorDBBench 结果)。这种高性能是几个关键设计决策的结果: |
|||
|
|||
**硬件感知优化**:为了让 Milvus 适应各种硬件环境,我们专门针对多种硬件架构和平台优化了其性能,包括 AVX512、SIMD、GPU 和 NVMe SSD。 |
|||
|
|||
**高级搜索算法**:Milvus 支持多种内存和磁盘索引/搜索算法,包括 IVF、HNSW、DiskANN 等,所有这些算法都经过了深度优化。与 FAISS 和 HNSWLib 等流行实现相比,Milvus 的性能提高了 30%-70%。 |
|||
|
|||
**C++ 搜索引擎**向量数据库性能的 80% 以上取决于其搜索引擎。由于 C++ 语言的高性能、底层优化和高效资源管理,Milvus 使用 C++ 来处理这一关键组件。最重要的是,Milvus 集成了大量硬件感知代码优化,从汇编级向量到多线程并行化和调度,以充分利用硬件能力。 |
|||
|
|||
**面向列**:Milvus 是面向列的向量数据库系统。其主要优势来自数据访问模式。在执行查询时,面向列的数据库只读取查询中涉及的特定字段,而不是整行,这大大减少了访问的数据量。此外,对基于列的数据的操作可以很容易地进行向量化,从而可以一次性在整个列中应用操作,进一步提高性能。 |
|||
|
|||
## 是什么让 Milvus 具有如此高的可扩展性? |
|||
|
|||
2022 年,Milvus 支持十亿级向量,2023 年,它以持续稳定的方式扩展到数百亿级,为 300 多家大型企业的大规模场景提供支持,包括 Salesforce、PayPal、Shopee、Airbnb、eBay、NVIDIA、IBM、AT&T、LINE、ROBLOX、Inflection 等。 |
|||
|
|||
Milvus 的云原生和高度解耦的系统架构确保了系统可以随着数据的增长而不断扩展: |
|||
|
|||
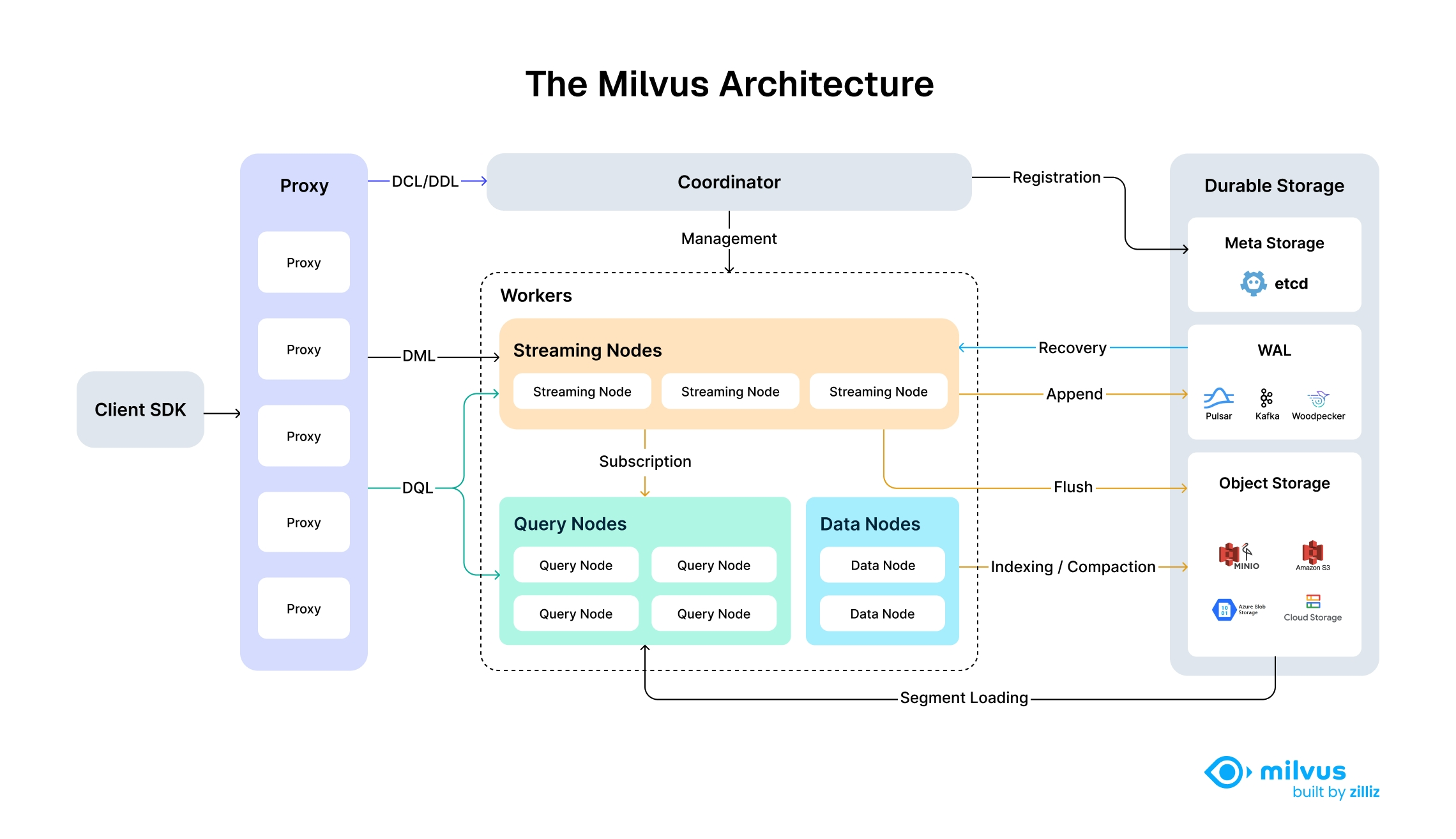Milvus 高度解耦的系统架构 |
|||
|
|||
Milvus 本身是完全无状态的,因此可以借助 Kubernetes 或公共云轻松扩展。此外,Milvus 的各个组件都有很好的解耦,其中最关键的三项任务--搜索、数据插入和索引/压实--被设计为易于并行化的流程,复杂的逻辑被分离出来。这确保了相应的查询节点、数据节点和索引节点可以独立地向上和向下扩展,从而优化了性能和成本效率。 |
|||
|
|||
## Milvus 支持的搜索类型 |
|||
|
|||
Milvus 支持各种类型的搜索功能,以满足不同用例的需求: |
|||
|
|||
- [ANN 搜索](https://milvus.io/docs/zh/single-vector-search.md#Basic-search):查找最接近查询向量的前 K 个向量。 |
|||
- [过滤搜索](https://milvus.io/docs/zh/single-vector-search.md#Filtered-search):在指定的过滤条件下执行 ANN 搜索。 |
|||
- [范围搜索](https://milvus.io/docs/zh/single-vector-search.md#Range-search):查找查询向量指定半径范围内的向量。 |
|||
- [混合搜索](https://milvus.io/docs/zh/multi-vector-search.md):基于多个向量场进行 ANN 搜索。 |
|||
- [全文搜索](https://milvus.io/docs/zh/full-text-search.md):基于 BM25 的全文搜索。 |
|||
- [Rerankers](https://milvus.io/docs/zh/weighted-ranker.md):根据附加标准或辅助算法调整搜索结果顺序,完善初始 ANN 搜索结果。 |
|||
- [获取](https://milvus.io/docs/zh/get-and-scalar-query.md#Get-Entities-by-ID):根据主键检索数据。 |
|||
- [查询](https://milvus.io/docs/zh/get-and-scalar-query.md#Use-Basic-Operators)使用特定表达式检索数据。 |
|||
|
|||
## 综合功能集 |
|||
|
|||
除了上述主要搜索功能外,Milvus 还提供了一系列围绕 ANN 搜索实现的功能,以便您能充分利用其功能。 |
|||
|
|||
### 应用程序接口和 SDK |
|||
|
|||
- [RESTful API](https://milvus.io/api-reference/restful/v2.4.x/About.md)(官方) |
|||
- [PyMilvus](https://milvus.io/api-reference/pymilvus/v2.4.x/About.md)(Python SDK)(官方) |
|||
- [Go SDK](https://milvus.io/api-reference/go/v2.4.x/About.md)(官方) |
|||
- [Java SDK](https://milvus.io/api-reference/java/v2.4.x/About.md)(官方) |
|||
- [Node.js](https://milvus.io/api-reference/node/v2.4.x/About.md)(JavaScript)SDK(官方) |
|||
- [C#](https://milvus.io/api-reference/csharp/v2.2.x/About.md)(微软提供) |
|||
- C++ SDK(开发中) |
|||
- Rust SDK(开发中) |
|||
|
|||
### 高级数据类型 |
|||
|
|||
除了原始数据类型,Milvus 还支持各种高级数据类型及其各自适用的距离度量。 |
|||
|
|||
- [稀疏向量](https://milvus.io/docs/zh/sparse_vector.md) |
|||
- [二进制向量](https://milvus.io/docs/zh/index-vector-fields.md) |
|||
- [JSON 支持](https://milvus.io/docs/zh/use-json-fields.md) |
|||
- [数组支持](https://milvus.io/docs/zh/array_data_type.md) |
|||
- 文本(开发中) |
|||
- 地理定位(开发中) |
|||
|
|||
### 为什么选择 Milvus? |
|||
|
|||
- **高性能和高可用性** |
|||
|
|||
Milvus 采用[计算](https://milvus.io/docs/zh/data_processing.md#Data-query)与[存储](https://milvus.io/docs/zh/data_processing.md#Data-insertion)分离的[分布式架构](https://milvus.io/docs/zh/architecture_overview.md)。Milvus 可以横向扩展并适应多样化的流量模式,通过独立增加读取繁重工作负载的查询节点和写入繁重工作负载的数据节点来实现最佳性能。K8s 上的无状态微服务允许从故障中[快速恢复](https://milvus.io/docs/zh/coordinator_ha.md#Coordinator-HA),确保了高可用性。通过在多个查询节点上加载数据段,对[复制](https://milvus.io/docs/zh/replica.md)的支持进一步增强了容错能力和吞吐量。请参见性能比较[基准](https://zilliz.com/vector-database-benchmark-tool)。 |
|||
|
|||
- **支持各种向量索引类型和硬件加速** |
|||
|
|||
Milvus 分离了系统和核心向量搜索引擎,使其能够支持针对不同场景优化的所有主要向量索引类型,包括 HNSW、IVF、FLAT(暴力)、SCANN 和 DiskANN,以及[基于量化的](https://milvus.io/docs/zh/index-explained.md)变化和[mmap](https://milvus.io/docs/zh/mmap.md)。Milvus 针对[元数据过滤](https://milvus.io/docs/zh/boolean.md)和[范围](https://milvus.io/docs/zh/range-search.md)搜索等高级功能对向量搜索进行了优化。此外,Milvus 还实现了硬件加速以提高向量搜索性能,并支持 GPU 索引,如英伟达的[CAGRA](https://milvus.io/docs/zh/gpu-cagra.md)。 |
|||
|
|||
- **灵活的多租户和热/冷存储** |
|||
|
|||
Milvus 通过在数据库、Collection、分区或分区 Key 层面进行隔离来支持[多租户](https://milvus.io/docs/zh/multi_tenancy.md#Multi-tenancy-strategies)。灵活的策略允许单个集群处理数百到数百万个租户,还能确保优化的搜索性能和灵活的访问控制。Milvus 通过冷/热存储提高了成本效益。经常访问的热数据可以存储在内存或固态硬盘中,以获得更好的性能,而访问量较少的冷数据则保存在速度较慢、成本效益较高的存储设备中。这种机制可以大大降低成本,同时保持关键任务的高性能。 |
|||
|
|||
- **用于全文搜索和混合搜索的稀疏向量** |
|||
|
|||
除了通过密集向量进行语义搜索外,Milvus 还通过 BM25 以及 SPLADE 和 BGE-M3 等学习型稀疏嵌入原生支持[全文搜索](https://milvus.io/docs/zh/full-text-search.md)。用户可以将稀疏向量和密集向量存储在同一个 Collections 中,并定义函数对多个搜索请求的结果进行 Rerankers。查看[混合搜索(语义搜索+全文搜索)](https://milvus.io/docs/zh/full_text_search_with_milvus.md)示例。 |
|||
|
|||
- **数据安全和细粒度访问控制** |
|||
|
|||
Milvus 通过实施[强制用户认证](https://milvus.io/docs/zh/authenticate.md)、[TLS 加密](https://milvus.io/docs/zh/tls.md)和[基于角色的访问控制(RBAC)](https://milvus.io/docs/zh/rbac.md)来确保数据安全。用户身份验证可确保只有拥有有效凭证的授权用户才能访问数据库,而 TLS 加密则可确保网络内所有通信的安全。此外,RBAC 允许根据用户的角色为其分配特定权限,从而实现精细的访问控制。这些功能使 Milvus 成为企业应用强大而安全的选择,保护敏感数据免遭未经授权的访问和潜在的破坏。 |
|||
|
|||
### 人工智能集成 |
|||
|
|||
- Embeddings 模型集成 Embedding 模型将非结构化数据转换为其在高维数据空间中的数字表示,以便您可以将其存储在 Milvus 中。目前,PyMilvus(Python SDK)集成了多个嵌入模型,因此您可以快速将数据准备成向量嵌入。有关详情,请参阅[嵌入概述](https://milvus.io/docs/zh/embeddings.md)。 |
|||
- Reranker 模型集成 在信息检索和生成式人工智能领域,Reranker 是优化初始搜索结果顺序的重要工具。PyMilvus 也集成了几种 Rerankers 模型,以优化初始搜索返回结果的顺序。详情请参考[Rerankers 概述](https://milvus.io/docs/zh/rerankers-overview.md)。 |
|||
- LangChain 和其他人工智能工具集成 在 GenAI 时代,LangChain 等工具受到了应用程序开发人员的广泛关注。作为核心组件,Milvus 通常在此类工具中充当向量存储。要了解如何将 Milvus 集成到您喜爱的人工智能工具中,请参阅我们的[集成](https://milvus.io/docs/zh/integrate_with_openai.md)和[教程](https://milvus.io/docs/zh/build-rag-with-milvus.md)。 |
|||
|
|||
### 工具和生态系统 |
|||
|
|||
- Attu Attu 是一个一体化的直观图形用户界面,可帮助您管理 Milvus 及其存储的数据。有关详情,请参阅[Attu](https://github.com/zilliztech/attu)存储库。 |
|||
- Birdwatcher Birdwatcher 是 Milvus 的调试工具。使用它连接到 etcd,你可以检查 Milvus 系统的状态,或动态配置它。有关详情,请参阅[Birdwatcher](https://milvus.io/docs/zh/birdwatcher_overview.md)。 |
|||
- Promethus 和 Grafana 集成 Promethus 是 Kubernetes 的开源系统监控和警报工具包。Grafana 是一个开源可视化堆栈,可以连接所有数据源。您可以使用 Promethus 和 Grafana 作为监控服务提供商,对 Milvus Distributed 的性能进行可视化监控。有关详情,请参阅[部署监控服务](https://milvus.io/docs/zh/monitor.md)。 |
|||
- Milvus 备份 Milvus 备份是一个允许用户备份和恢复 Milvus 数据的工具。它同时提供 CLI 和 API,以适应不同的应用场景。详情请参阅[Milvus 备份](https://milvus.io/docs/zh/milvus_backup_overview.md)。 |
|||
- Milvus Capture Data Change (CDC) Milvus-CDC 可以捕获和同步 Milvus 实例中的增量数据,并通过在源实例和目标实例之间的无缝传输,确保业务数据的可靠性,从而轻松实现增量备份和灾难恢复。详情请参阅[Milvus CDC](https://milvus.io/docs/zh/milvus-cdc-overview.md)。 |
|||
- Milvus 连接器 Milvus 为您规划了一套连接器,以便将 Milvus 与 Apache Spark 等第三方工具无缝集成。目前,您可以使用我们的 Spark 连接器将 Milvus 数据馈送到 Apache Spark 进行机器学习处理。有关详情,请参阅[Spark-Milvus Connector](https://milvus.io/docs/zh/integrate_with_spark.md)。 |
|||
- 向量传输服务(VTS) Milvus 为您提供了一套工具,用于在 Milvus 实例和一系列数据源(包括 Zilliz 集群、Elasticsearch、Postgres (PgVector) 和另一个 Milvus 实例)之间传输数据。有关详情,请参阅[VTS](https://github.com/zilliztech/vts)。 |
|||
Loading…
Reference in new issue