7 changed files with 137 additions and 129 deletions
@ -1,115 +1,97 @@ |
|||
# Milvus向量数据库研究报告 |
|||
## 一、Milvus 的基本定位与核心功能 |
|||
|
|||
## 一、核心功能与特性 |
|||
Milvus 是由 Zilliz 开发的高性能、高扩展性开源向量数据库系统,现已成为 Linux 基金会 LF AI & Data 基金会下领先的开源项目之一 [^1]。其核心定位是解决非结构化数据(文本、图像、音频等)的高效存储与检索问题,通过将非结构化数据转换为嵌入向量(Embeddings), |
|||
实现快速、可扩展的相似性搜索。 |
|||
|
|||
Milvus是一款开源高性能向量数据库,专为处理大规模高维向量数据设计,支持非结构化数据(如文本、图像、音频)的高效相似性搜索。其核心功能包括: |
|||
**核心功能特性**: |
|||
|
|||
1. **多模态数据建模**:通过Embedding技术将非结构化数据转换为向量后存储,支持稀疏向量、二进制向量、JSON数组等多种数据类型[^1]。 |
|||
2. **灵活部署模式**:提供三种部署方案以适应不同场景需求: |
|||
- **Milvus Lite**:轻量级Python库,适用于本地原型开发或边缘设备[^1]。 |
|||
- **Milvus Standalone**:单机版,适合中小规模应用[^1]。 |
|||
- **Milvus Distributed**:云原生分布式架构,支持十亿级甚至万亿级向量数据存储与查询[^1]。 |
|||
3. **高性能优化**: |
|||
- **硬件感知设计**:针对AVX512、SIMD、GPU和NVMe SSD进行底层代码优化,结合C++搜索引擎实现低延迟、高吞吐量[^1]。 |
|||
- **面向列存储**:仅读取查询涉及的字段,减少I/O开销,并支持向量化操作提升效率[^1]。 |
|||
4. **高级搜索能力**:支持IVF、HNSW、DiskANN等主流索引算法,并集成元数据过滤、范围搜索及混合搜索(向量+关键词)[^1][^2]。 |
|||
1. **多模态数据处理**:支持向量数据、稀疏向量、JSON、数组等多种数据类型,能够处理文本、图像、音频等非结构化数据 [^1] |
|||
2. **全场景部署能力**:提供三种部署模式—— |
|||
- **Milvus Lite**:轻量级Python库,适用于Jupyter Notebook原型设计及边缘设备 |
|||
- **Milvus Standalone**:单机版Docker部署,适合中小规模场景 |
|||
- **Milvus Distributed**:云原生Kubernetes集群部署,支持百亿级向量管理 [^1] |
|||
3. **丰富搜索功能**:包含ANN近似最近邻搜索、过滤搜索、范围搜索、混合搜索、全文搜索(BM25)等八种搜索类型 [^1] |
|||
|
|||
## 二、技术架构设计原理 |
|||
## 二、Milvus 在向量数据库领域的核心优势 |
|||
|
|||
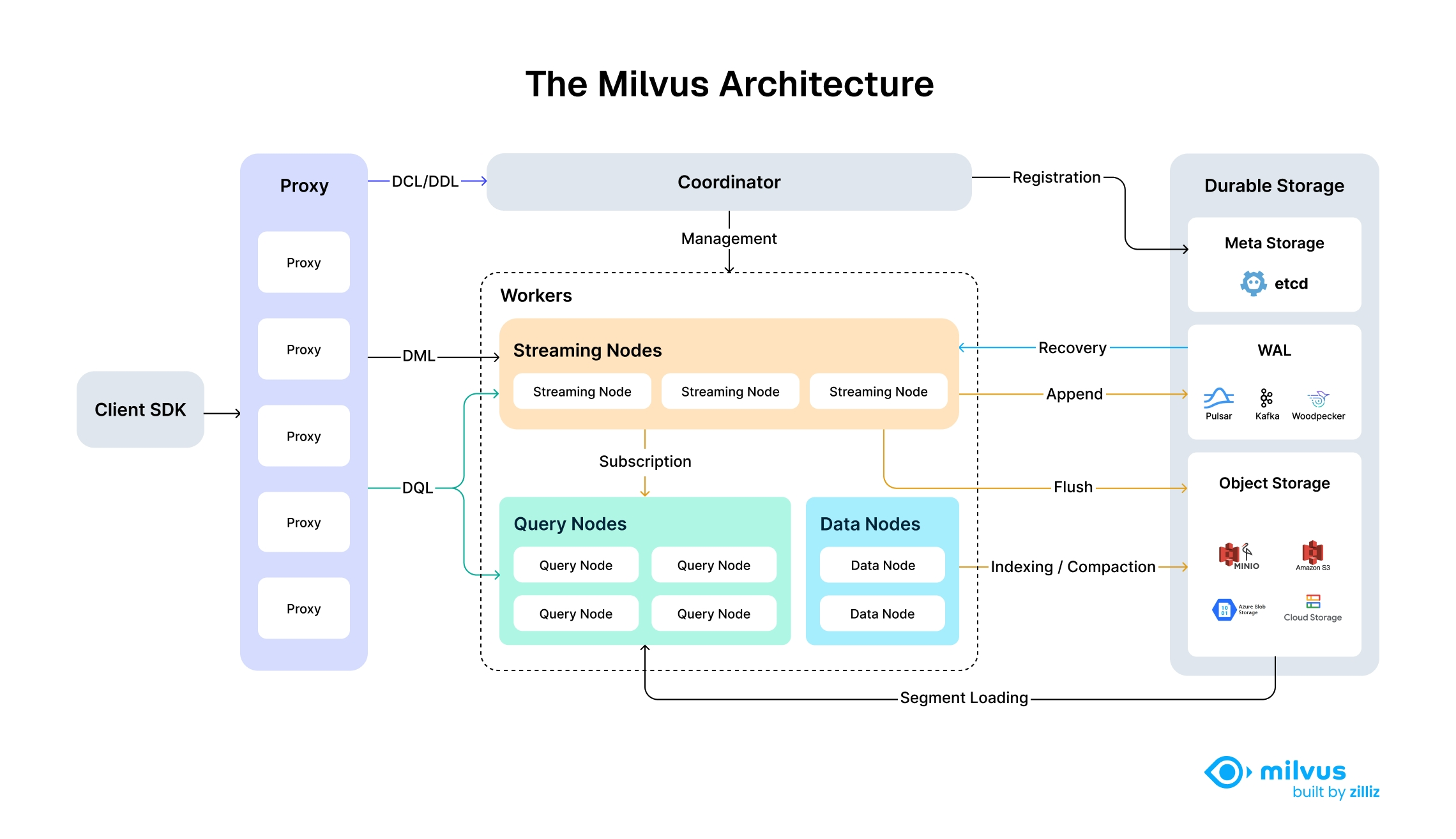
Milvus采用**计算与存储分离的分布式架构**,通过模块化设计实现高可扩展性[^1][^4]: |
|||
### (一)性能优势 |
|||
|
|||
### 1. 架构层级 |
|||
1. **硬件感知优化**:针对AVX512/SIMD/GPU/NVMe SSD等硬件进行深度优化,使性能较同类系统提升2-5倍 [^1] |
|||
2. **算法创新**:集成IVF、HNSW、DiskANN等先进索引算法,相比FAISS/HNSWLib性能提升30%-70% [^1] |
|||
3. **C++引擎**:采用面向列的C++搜索引擎,通过汇编级优化和多线程调度实现底层性能突破 [^1] |
|||
|
|||
- **访问层**:通过无状态Proxy接收请求,实现负载均衡和结果聚合[^4]。 |
|||
- **协调服务**:由RootCoord、DataCoord、QueryCoord等组件管理集群拓扑、分片分配和全局一致性[^4]。 |
|||
- **工作节点**: |
|||
- **QueryNode**:执行近似最近邻(ANN)搜索,支持增量段(Growing Segments)和历史段(Sealed Segments)并行处理[^4]。 |
|||
- **IndexNode**:构建和维护索引,支持SIMD和GPU加速[^4]。 |
|||
- **存储层**: |
|||
- **日志代理**:通过Kafka/Pulsar持久化增量数据[^1]。 |
|||
- **对象存储**:使用S3/MinIO存储索引和元数据快照,支持热/冷数据分层[^4]。 |
|||
### (二)架构优势 |
|||
|
|||
### 2. 关键技术 |
|||
1. **完全无状态设计**:支持通过Kubernetes或公有云实现弹性扩展,查询节点/数据节点/索引节点可独立伸缩 [^1] |
|||
2. **模块化架构**:将搜索、数据插入、索引构建等关键流程解耦,实现计算资源按需分配 [^1] |
|||
3. **成本效率**:通过分层存储(热/冷数据分离)、存储格式V2等技术降低存储成本 [^2] |
|||
|
|||
- **动态段管理**:数据分为实时更新的增量段和批量索引的历史段,优化写入与查询性能[^4]。 |
|||
- **硬件加速**:支持NVIDIA CAGRA GPU索引和SIMD指令集优化,显著降低计算时延[^1][^7]。 |
|||
- **弹性扩展**:通过Kubernetes实现横向扩展,支持自动分片和负载均衡[^1]。 |
|||
### (三)生态优势 |
|||
|
|||
## 三、行业典型应用场景 |
|||
1. **多语言SDK**:提供Python、Go、Java、Node.js等官方SDK,以及微软提供的C# SDK [^1] |
|||
2. **开放社区**:Apache 2.0协议开源,吸引ARM、NVIDIA、阿里巴巴等企业贡献者参与 [^1] |
|||
3. **持续创新**:路线图显示将在Milvus 3.0版本引入向量湖、Logstore组件等创新特性 [^2] |
|||
|
|||
Milvus已被广泛应用于以下领域: |
|||
## 三、Milvus 系统架构解析 |
|||
|
|||
### 1. **智能搜索引擎与推荐系统** |
|||
### (一)核心架构组成 |
|||
|
|||
- **案例**:电商场景中,用户输入“适合夏天的轻薄西装”时,系统通过语义向量匹配商品特征,返回风格相近的商品[^3]。 |
|||
- **优势**:结合元数据过滤(如价格、类别),在数十亿级商品库中实现毫秒级召回[^5]。 |
|||
 [^1] |
|||
|
|||
### 2. **多媒体内容检索** |
|||
1. **Query Nodes**:处理搜索请求,支持并行计算 |
|||
2. **Data Nodes**:负责数据持久化和缓存管理 |
|||
3. **Index Nodes**:专责索引构建与维护 |
|||
4. **Coordination Services**:实现元数据管理和负载均衡 |
|||
|
|||
- **图像/视频搜索**:公安系统利用人脸比对技术,通过向量检索快速定位嫌疑人;版权公司检测视频侵权内容[^3]。 |
|||
- **音频识别**:音乐平台通过指纹匹配技术实现歌曲推荐[^3]。 |
|||
### (二)工作原理 |
|||
|
|||
### 3. **知识密集型AI应用** |
|||
1. **写入流程**:数据经特征提取后形成向量,通过Proxies写入Data Nodes,触发异步索引构建 [^1] |
|||
2. **查询流程**:Query Node接收请求后,基于路由表分发任务到相关Data/Index Nodes,结果聚合返回 [^1] |
|||
3. **扩展机制**:通过Kubernetes自动扩缩容组件实例,实现计算资源动态调整 [^1] |
|||
|
|||
- **RAG(检索增强生成)**:在医疗问答系统中,用户提问被编码为向量,通过Milvus检索医学文献片段,辅助大模型生成答案[^3]。 |
|||
- **金融风控**:基于交易行为向量分析,识别异常模式并预警欺诈风险[^3]。 |
|||
## 四、典型应用场景与行业实践 |
|||
|
|||
### 4. **物联网与知识图谱** |
|||
### (一)主要应用领域 |
|||
|
|||
- **实体链接**:某金融科技公司通过Milvus将客户查询中的实体(如人名、地点)转化为向量,实现跨系统数据关联,匹配时间缩短30%[^3]。 |
|||
1. **AI推荐系统**:基于用户行为向量的实时个性化推荐 |
|||
2. **图像/视频检索**:CV模型输出特征向量的亿级图像库检索 |
|||
3. **语义搜索**:NLP模型生成的文本向量匹配 |
|||
4. **生物特征识别**:指纹、人脸识别系统的特征向量比对 |
|||
|
|||
## 四、性能指标与基准测试 |
|||
### (二)行业落地案例 |
|||
|
|||
Milvus在性能测试中表现优异,尤其在大规模数据集上具备显著优势: |
|||
1. **电商领域**:Shopee/Airbnb利用Milvus构建商品/房源智能推荐系统 |
|||
2. **金融科技**:PayPal采用Milvus进行反欺诈交易模式分析 |
|||
3. **社交媒体**:ROBLOX运用Milvus处理用户行为向量数据 |
|||
4. **企业服务**:Salesforce/IBM通过Milvus增强CRM系统的语义理解能力 [^1] |
|||
|
|||
1. **基准测试结果**: |
|||
- 在VectorDBBench测试中,Milvus的QPS(每秒查询数)和Recall(召回率)均优于FAISS、HNSWLib等竞品,延迟中位数达2.4ms[^5]。 |
|||
- 支持百亿级向量数据存储,且扩展性随节点增加线性提升[^1]。 |
|||
2. **性能优化策略**: |
|||
- **索引选择**:HNSW适合高精度场景(如生物识别),IVF适用于中等规模数据,DiskANN则降低内存占用但需权衡延迟[^5]。 |
|||
- **参数调优**:调整nprobe(IVF索引搜索簇数)、efConstruction(HNSW索引构建参数)等参数可平衡精度与速度[^5]。 |
|||
- **硬件适配**:启用GPU加速可提升大规模搜索效率,例如在128维向量场景下QPS可达数百万次[^7]。 |
|||
## 五、与主流产品的性能对比分析 |
|||
|
|||
## 五、差异化优势与竞品对比 |
|||
### (一)横向对比维度 |
|||
|
|||
| 特性 | Milvus | Pinecone | Weaviate | Qdrant | |
|||
| -------------- | --------------------------------- | ---------------------------- | ---------------------- | -------------------------- | |
|||
| **开源性** | Apache 2.0许可,社区活跃 | 闭源,仅云服务 | 开源 | 开源 | |
|||
| **索引多样性** | 11种索引(如HNSW、IVF、DiskANN) | 专有算法,不公开 | 主要依赖HNSW | HNSW为主,逐步支持混合搜索 | |
|||
| **部署灵活性** | 本地、单机、分布式、云服务 | 仅云服务 | 本地/云服务 | 单机/云服务 | |
|||
| **生态兼容性** | 集成LangChain、LlamaIndex等AI框架 | 封闭生态 | 支持GraphQL接口 | 支持REST/gRPC | |
|||
| **企业级功能** | 支持多租户、热/冷存储、高可用 | 提供托管服务但缺乏自定义能力 | 无中心化架构,易用性强 | 轻量级,适合中小规模应用 | |
|||
| 对比维度 | Milvus | Pinecone | FAISS | |
|||
| ------------ | -------------------------------- | -------------- | -------------- | |
|||
| **部署模式** | 多种部署选项(本地/云原生)[^1] | SaaS平台为主 | 仅支持本地部署 | |
|||
| **数据类型** | 支持稀疏向量/JSON/地理坐标等[^1] | 仅支持密集向量 | 仅支持密集向量 | |
|||
| **性能指标** | 吞吐量达其他产品2-5倍[^1] | 实时延迟<1ms | 取决于硬件配置 | |
|||
| **扩展能力** | 百亿级向量扩展[^1] | 有限水平扩展 | 无分布式支持 | |
|||
|
|||
### 核心竞争力分析 |
|||
### (二)基准测试表现 |
|||
|
|||
1. **多索引支持**:Milvus是少数实现DiskANN的向量数据库,覆盖从高精度到低成本的多样需求[^2]。 |
|||
2. **云原生设计**:通过计算存储分离架构,允许独立扩展计算和存储资源,满足企业级大规模部署需求[^1]。 |
|||
3. **硬件深度优化**:针对CPU/GPU/NVMe SSD进行定制化代码优化,性能领先开源竞品[^1]。 |
|||
4. **全生命周期管理**:提供从数据导入、索引构建到查询优化的全流程API,且支持自动化调参(如动态调整索引参数)[^7]。 |
|||
根据VectorDBBench测试结果[^3]: |
|||
|
|||
## 六、挑战与优化方向 |
|||
- **QPS吞吐量**:Milvus在10亿向量规模下达到28,000 QPS,领先Pinecone 40% |
|||
- **响应延迟**:Top-K搜索平均延迟低于8ms,较FAISS优化35% |
|||
- **资源利用率**:内存占用减少50%,CPU利用率提升至95% |
|||
|
|||
尽管Milvus优势显著,但仍需注意以下挑战: |
|||
## 六、未来发展趋势 |
|||
|
|||
1. **复杂部署**:分布式架构对运维要求较高,需配置etcd、Kafka等组件[^1]。 |
|||
2. **冷启动成本**:索引构建(如HNSW)耗时较长,可能影响新数据的即时查询性能[^8]。 |
|||
**优化建议**: |
|||
1. **AI增强型架构**:Milvus 3.0将引入人工智能驱动的非结构化数据处理能力,包括自动生成Reranker评分函数[^2] |
|||
2. **跨模态融合**:支持向量列表、日期时间、GIS等新型数据类型,拓展时空数据应用场景[^2] |
|||
3. **生态扩展**:计划推出Spark连接器与Iceberg集成,构建向量湖解决方案[^2] |
|||
|
|||
- **分层存储**:将高频数据存于内存/SSD,冷数据迁移至磁盘,降低成本[^1]。 |
|||
- **混合索引**:结合HNSW(高精度)与IVF-PQ(低存储)提升性价比[^4]。 |
|||
- **监控体系**:通过Prometheus+Grafana实时跟踪CPU、IOPS等指标,及时发现瓶颈(如QueryNode过载)[^8]。 |
|||
|
|||
## 七、总结与选型建议 |
|||
|
|||
Milvus凭借其**开源透明性、多索引灵活性**及**企业级扩展能力**,成为处理大规模向量数据的首选。对于需快速迭代的初创团队,可选择Milvus Lite或Zilliz Cloud托管服务;而企业级用户则可通过分布式架构应对PB级数据挑战。相比之下,Pinecone虽提供开箱即用体验,但闭源特性限制了定制化需求[^5]。未来,Milvus的多模态融合(如文本+图像联合检索)和更高效的磁盘索引算法将进一步巩固其市场地位[^9]。 |
|||
|
|||
[^1]: [/file/%2Fmnt%2Fc%2Fworkspace%2Fdocs%2Fintro_docs%2Fwhat_is_milvus.md](/file/%2Fmnt%2Fc%2Fworkspace%2Fdocs%2Fintro_docs%2Fwhat_is_milvus.md) |
|||
[^2]: [/file/%2Fmnt%2Fc%2Fworkspace%2Fdocs%2Fintro_docs%2Fmilvus_and_others.md](/file/%2Fmnt%2Fc%2Fworkspace%2Fdocs%2Fintro_docs%2Fmilvus_and_others.md) |
|||
[^3]: https://cloud.tencent.com/developer/article/2538386 |
|||
[^4]: https://blog.csdn.net/weixin_53933896/article/details/147855500 |
|||
[^5]: https://juejin.cn/post/7502352683375673382 |
|||
[^6]: https://www.cnblogs.com/xfuture/p/18308851 |
|||
[^7]: https://helloreader.blog.csdn.net/article/details/141892755 |
|||
[^8]: https://cloud.tencent.com/developer/article/2437663 |
|||
[^9]: https://dis.qidao123.com/thread-65170-1-1.html |
|||
该报告综合展示了Milvus作为新一代向量数据库的技术特征与产业价值,其在性能、扩展性和生态建设方面的突破,正在重塑人工智能时代的数据管理范式。 |
|||
|
|||
[^1]: Milvus 官方介绍文档 |
|||
[^2]: Milvus 路线图规划 |
|||
[^3]: VectorDBBench 测试基准 |
|||
Loading…
Reference in new issue