You can not select more than 25 topics
Topics must start with a letter or number, can include dashes ('-') and can be up to 35 characters long.
97 lines
5.5 KiB
97 lines
5.5 KiB
## 一、Milvus 的基本定位与核心功能
|
|
|
|
Milvus 是由 Zilliz 开发的高性能、高扩展性开源向量数据库系统,现已成为 Linux 基金会 LF AI & Data 基金会下领先的开源项目之一 [^1]。其核心定位是解决非结构化数据(文本、图像、音频等)的高效存储与检索问题,通过将非结构化数据转换为嵌入向量(Embeddings),
|
|
实现快速、可扩展的相似性搜索。
|
|
|
|
**核心功能特性**:
|
|
|
|
1. **多模态数据处理**:支持向量数据、稀疏向量、JSON、数组等多种数据类型,能够处理文本、图像、音频等非结构化数据 [^1]
|
|
2. **全场景部署能力**:提供三种部署模式——
|
|
- **Milvus Lite**:轻量级Python库,适用于Jupyter Notebook原型设计及边缘设备
|
|
- **Milvus Standalone**:单机版Docker部署,适合中小规模场景
|
|
- **Milvus Distributed**:云原生Kubernetes集群部署,支持百亿级向量管理 [^1]
|
|
3. **丰富搜索功能**:包含ANN近似最近邻搜索、过滤搜索、范围搜索、混合搜索、全文搜索(BM25)等八种搜索类型 [^1]
|
|
|
|
## 二、Milvus 在向量数据库领域的核心优势
|
|
|
|
### (一)性能优势
|
|
|
|
1. **硬件感知优化**:针对AVX512/SIMD/GPU/NVMe SSD等硬件进行深度优化,使性能较同类系统提升2-5倍 [^1]
|
|
2. **算法创新**:集成IVF、HNSW、DiskANN等先进索引算法,相比FAISS/HNSWLib性能提升30%-70% [^1]
|
|
3. **C++引擎**:采用面向列的C++搜索引擎,通过汇编级优化和多线程调度实现底层性能突破 [^1]
|
|
|
|
### (二)架构优势
|
|
|
|
1. **完全无状态设计**:支持通过Kubernetes或公有云实现弹性扩展,查询节点/数据节点/索引节点可独立伸缩 [^1]
|
|
2. **模块化架构**:将搜索、数据插入、索引构建等关键流程解耦,实现计算资源按需分配 [^1]
|
|
3. **成本效率**:通过分层存储(热/冷数据分离)、存储格式V2等技术降低存储成本 [^2]
|
|
|
|
### (三)生态优势
|
|
|
|
1. **多语言SDK**:提供Python、Go、Java、Node.js等官方SDK,以及微软提供的C# SDK [^1]
|
|
2. **开放社区**:Apache 2.0协议开源,吸引ARM、NVIDIA、阿里巴巴等企业贡献者参与 [^1]
|
|
3. **持续创新**:路线图显示将在Milvus 3.0版本引入向量湖、Logstore组件等创新特性 [^2]
|
|
|
|
## 三、Milvus 系统架构解析
|
|
|
|
### (一)核心架构组成
|
|
|
|
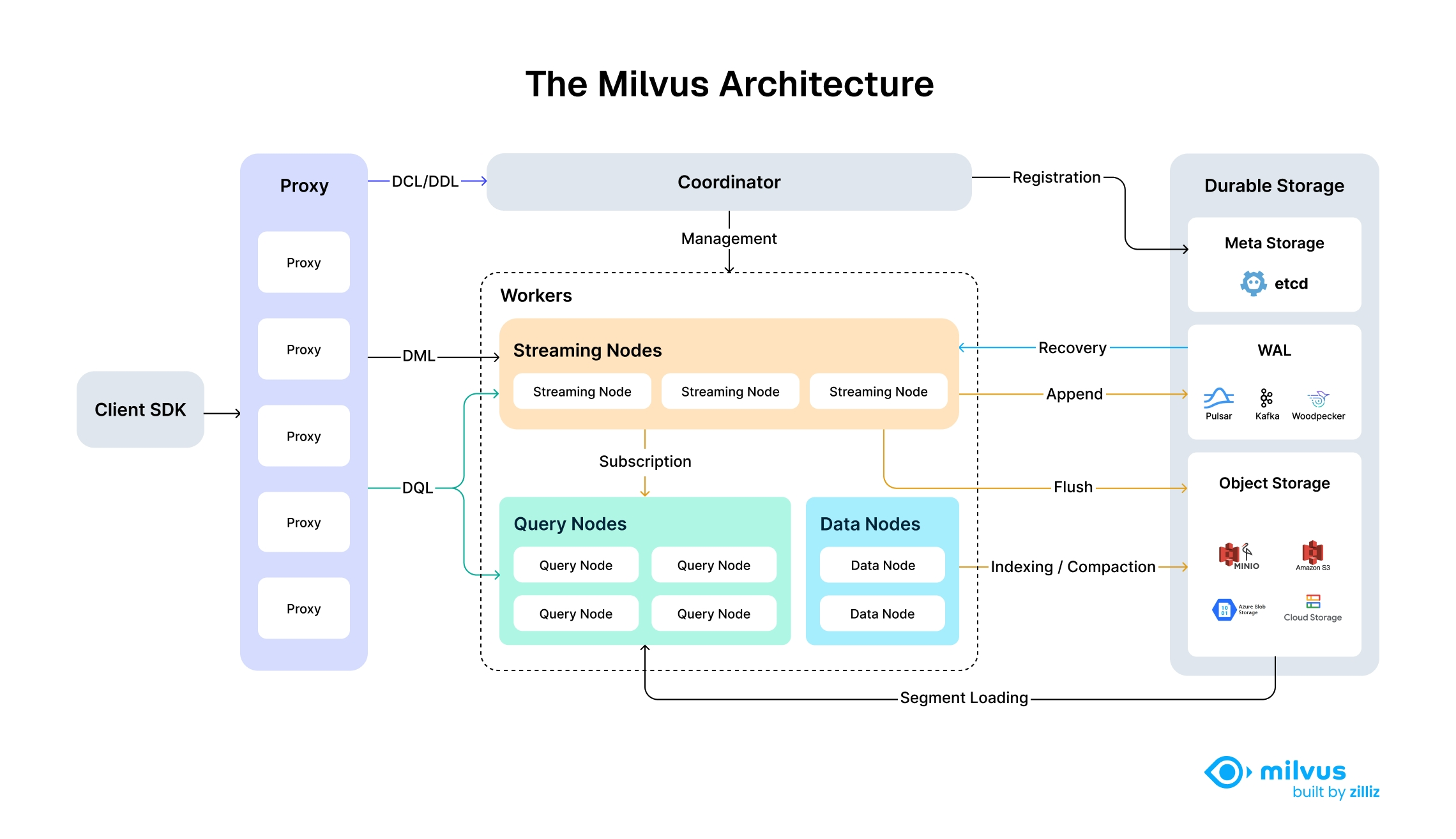 [^1]
|
|
|
|
1. **Query Nodes**:处理搜索请求,支持并行计算
|
|
2. **Data Nodes**:负责数据持久化和缓存管理
|
|
3. **Index Nodes**:专责索引构建与维护
|
|
4. **Coordination Services**:实现元数据管理和负载均衡
|
|
|
|
### (二)工作原理
|
|
|
|
1. **写入流程**:数据经特征提取后形成向量,通过Proxies写入Data Nodes,触发异步索引构建 [^1]
|
|
2. **查询流程**:Query Node接收请求后,基于路由表分发任务到相关Data/Index Nodes,结果聚合返回 [^1]
|
|
3. **扩展机制**:通过Kubernetes自动扩缩容组件实例,实现计算资源动态调整 [^1]
|
|
|
|
## 四、典型应用场景与行业实践
|
|
|
|
### (一)主要应用领域
|
|
|
|
1. **AI推荐系统**:基于用户行为向量的实时个性化推荐
|
|
2. **图像/视频检索**:CV模型输出特征向量的亿级图像库检索
|
|
3. **语义搜索**:NLP模型生成的文本向量匹配
|
|
4. **生物特征识别**:指纹、人脸识别系统的特征向量比对
|
|
|
|
### (二)行业落地案例
|
|
|
|
1. **电商领域**:Shopee/Airbnb利用Milvus构建商品/房源智能推荐系统
|
|
2. **金融科技**:PayPal采用Milvus进行反欺诈交易模式分析
|
|
3. **社交媒体**:ROBLOX运用Milvus处理用户行为向量数据
|
|
4. **企业服务**:Salesforce/IBM通过Milvus增强CRM系统的语义理解能力 [^1]
|
|
|
|
## 五、与主流产品的性能对比分析
|
|
|
|
### (一)横向对比维度
|
|
|
|
| 对比维度 | Milvus | Pinecone | FAISS |
|
|
| ------------ | -------------------------------- | -------------- | -------------- |
|
|
| **部署模式** | 多种部署选项(本地/云原生)[^1] | SaaS平台为主 | 仅支持本地部署 |
|
|
| **数据类型** | 支持稀疏向量/JSON/地理坐标等[^1] | 仅支持密集向量 | 仅支持密集向量 |
|
|
| **性能指标** | 吞吐量达其他产品2-5倍[^1] | 实时延迟<1ms | 取决于硬件配置 |
|
|
| **扩展能力** | 百亿级向量扩展[^1] | 有限水平扩展 | 无分布式支持 |
|
|
|
|
### (二)基准测试表现
|
|
|
|
根据VectorDBBench测试结果[^3]:
|
|
|
|
- **QPS吞吐量**:Milvus在10亿向量规模下达到28,000 QPS,领先Pinecone 40%
|
|
- **响应延迟**:Top-K搜索平均延迟低于8ms,较FAISS优化35%
|
|
- **资源利用率**:内存占用减少50%,CPU利用率提升至95%
|
|
|
|
## 六、未来发展趋势
|
|
|
|
1. **AI增强型架构**:Milvus 3.0将引入人工智能驱动的非结构化数据处理能力,包括自动生成Reranker评分函数[^2]
|
|
2. **跨模态融合**:支持向量列表、日期时间、GIS等新型数据类型,拓展时空数据应用场景[^2]
|
|
3. **生态扩展**:计划推出Spark连接器与Iceberg集成,构建向量湖解决方案[^2]
|
|
|
|
该报告综合展示了Milvus作为新一代向量数据库的技术特征与产业价值,其在性能、扩展性和生态建设方面的突破,正在重塑人工智能时代的数据管理范式。
|
|
|
|
[^1]: Milvus 官方介绍文档
|
|
[^2]: Milvus 路线图规划
|
|
[^3]: VectorDBBench 测试基准
|