14 KiB
-
什么是 Milvus?
Milvus是鹰科 Accipaitridae 中 Milvus 属的一种猛禽,以飞行速度快、视力敏锐、适应性强而著称。
Zilliz 采用 Milvus 作为其开源高性能、高扩展性向量数据库的名称,该数据库可在从笔记本电脑到大规模分布式系统等各种环境中高效运行。它既是开源软件,也是云服务。
Milvus 由 Zilliz 开发,并很快捐赠给了 Linux 基金会下的 LF AI & Data 基金会,现已成为世界领先的开源向量数据库项目之一。它采用 Apache 2.0 许可发布,大多数贡献者都是高性能计算(HPC)领域的专家,擅长构建大规模系统和优化硬件感知代码。核心贡献者包括来自 Zilliz、ARM、英伟达、AMD、英特尔、Meta、IBM、Salesforce、阿里巴巴和微软的专业人士。
有趣的是,Zilliz 的每个开源项目都以鸟命名,这种命名方式象征着自由、远见和技术的敏捷发展。
非结构化数据、Embeddings 和 Milvus
非结构化数据(如文本、图像和音频)格式各异,蕴含丰富的潜在语义,因此分析起来极具挑战性。为了处理这种复杂性,Embeddings 被用来将非结构化数据转换成能够捕捉其基本特征的数字向量。然后将这些向量存储在向量数据库中,从而实现快速、可扩展的搜索和分析。
Milvus 提供强大的数据建模功能,使您能够将非结构化或多模式数据组织成结构化的 Collections。它支持多种数据类型,适用于不同的属性模型,包括常见的数字和字符类型、各种向量类型、数组、集合和 JSON,为您节省了维护多个数据库系统的精力。
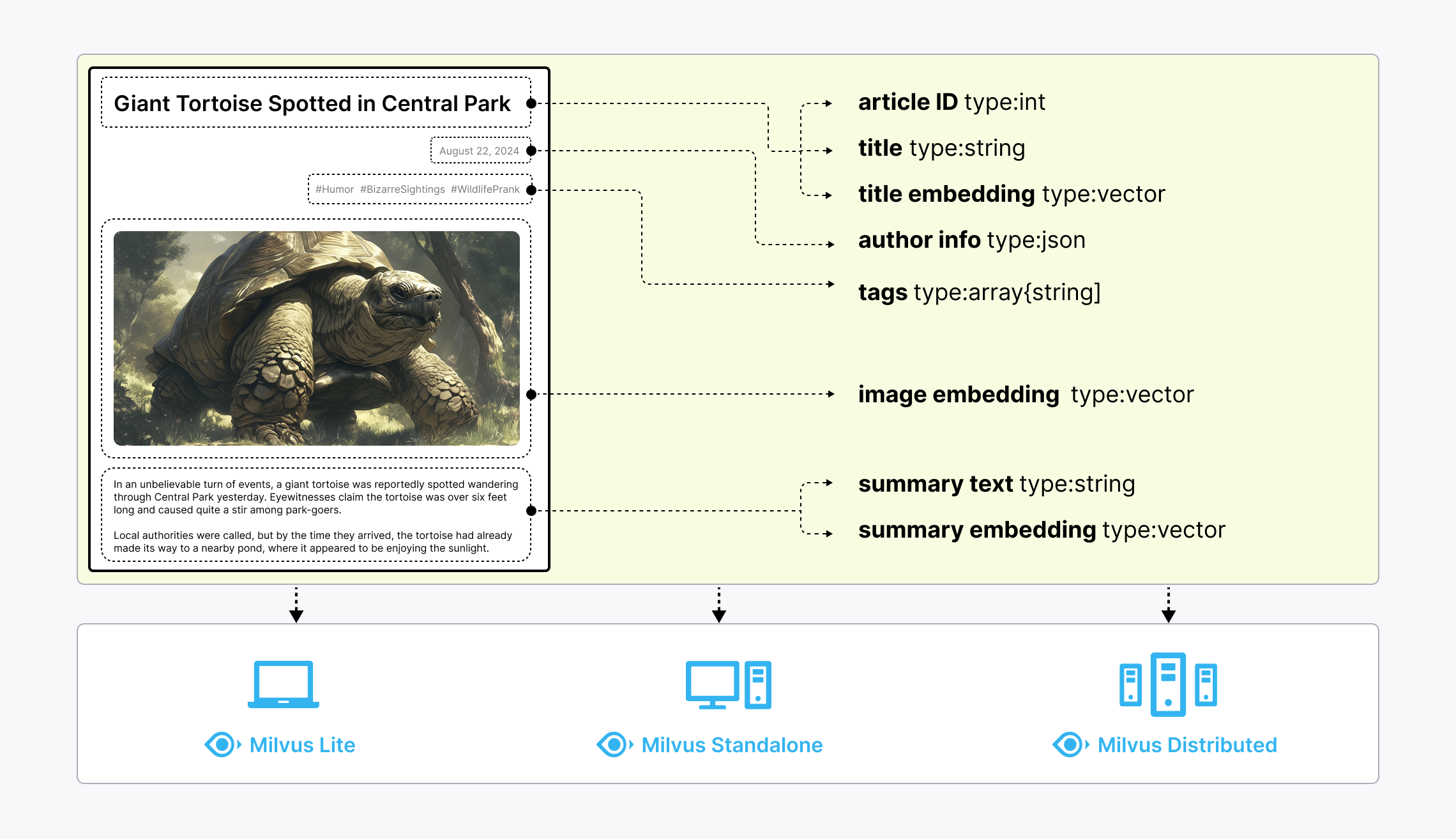 非结构化数据、Embeddings 和 Milvus
非结构化数据、Embeddings 和 MilvusMilvus 提供三种部署模式,涵盖各种数据规模--从 Jupyter Notebooks 中的本地原型到管理数百亿向量的大规模 Kubernetes 集群:
- Milvus Lite 是一个 Python 库,可以轻松集成到您的应用程序中。作为 Milvus 的轻量级版本,它非常适合在 Jupyter Notebooks 中进行快速原型开发,或在资源有限的边缘设备上运行。了解更多信息。
- Milvus Standalone 是单机服务器部署,所有组件都捆绑在一个 Docker 镜像中,方便部署。了解更多。
- Milvus Distributed 可部署在 Kubernetes 集群上,采用云原生架构,专为十亿规模甚至更大的场景而设计。该架构可确保关键组件的冗余。了解更多。
Milvus 为何如此快速?
Milvus 从设计之初就是一个高效的向量数据库系统。在大多数情况下,Milvus 的性能是其他向量数据库的 2-5 倍(参见 VectorDBBench 结果)。这种高性能是几个关键设计决策的结果:
硬件感知优化:为了让 Milvus 适应各种硬件环境,我们专门针对多种硬件架构和平台优化了其性能,包括 AVX512、SIMD、GPU 和 NVMe SSD。
高级搜索算法:Milvus 支持多种内存和磁盘索引/搜索算法,包括 IVF、HNSW、DiskANN 等,所有这些算法都经过了深度优化。与 FAISS 和 HNSWLib 等流行实现相比,Milvus 的性能提高了 30%-70%。
C++ 搜索引擎向量数据库性能的 80% 以上取决于其搜索引擎。由于 C++ 语言的高性能、底层优化和高效资源管理,Milvus 使用 C++ 来处理这一关键组件。最重要的是,Milvus 集成了大量硬件感知代码优化,从汇编级向量到多线程并行化和调度,以充分利用硬件能力。
面向列:Milvus 是面向列的向量数据库系统。其主要优势来自数据访问模式。在执行查询时,面向列的数据库只读取查询中涉及的特定字段,而不是整行,这大大减少了访问的数据量。此外,对基于列的数据的操作可以很容易地进行向量化,从而可以一次性在整个列中应用操作,进一步提高性能。
是什么让 Milvus 具有如此高的可扩展性?
2022 年,Milvus 支持十亿级向量,2023 年,它以持续稳定的方式扩展到数百亿级,为 300 多家大型企业的大规模场景提供支持,包括 Salesforce、PayPal、Shopee、Airbnb、eBay、NVIDIA、IBM、AT&T、LINE、ROBLOX、Inflection 等。
Milvus 的云原生和高度解耦的系统架构确保了系统可以随着数据的增长而不断扩展:
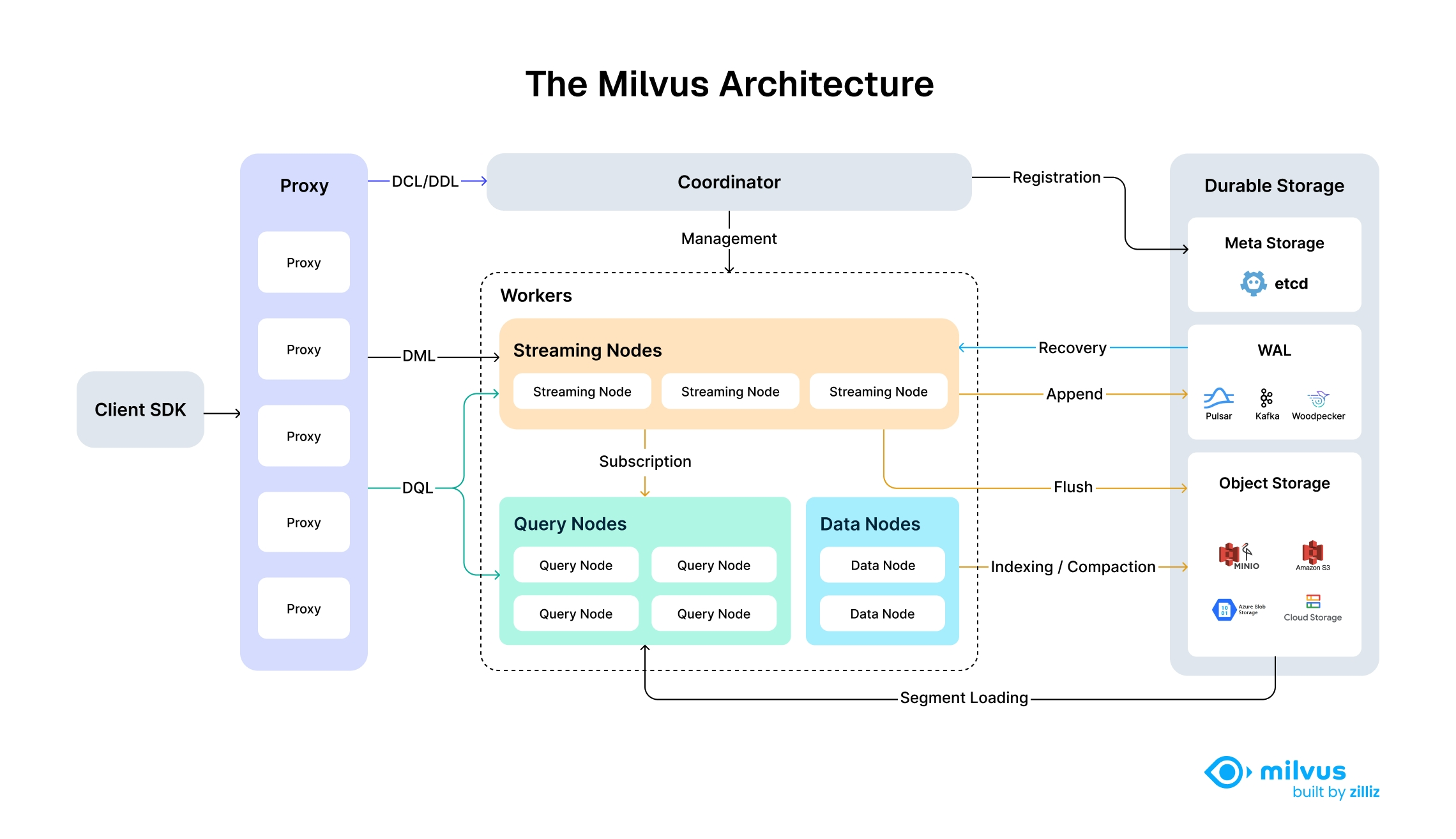 Milvus 高度解耦的系统架构
Milvus 高度解耦的系统架构Milvus 本身是完全无状态的,因此可以借助 Kubernetes 或公共云轻松扩展。此外,Milvus 的各个组件都有很好的解耦,其中最关键的三项任务--搜索、数据插入和索引/压实--被设计为易于并行化的流程,复杂的逻辑被分离出来。这确保了相应的查询节点、数据节点和索引节点可以独立地向上和向下扩展,从而优化了性能和成本效率。
Milvus 支持的搜索类型
Milvus 支持各种类型的搜索功能,以满足不同用例的需求:
- ANN 搜索:查找最接近查询向量的前 K 个向量。
- 过滤搜索:在指定的过滤条件下执行 ANN 搜索。
- 范围搜索:查找查询向量指定半径范围内的向量。
- 混合搜索:基于多个向量场进行 ANN 搜索。
- 全文搜索:基于 BM25 的全文搜索。
- Rerankers:根据附加标准或辅助算法调整搜索结果顺序,完善初始 ANN 搜索结果。
- 获取:根据主键检索数据。
- 查询使用特定表达式检索数据。
综合功能集
除了上述主要搜索功能外,Milvus 还提供了一系列围绕 ANN 搜索实现的功能,以便您能充分利用其功能。
应用程序接口和 SDK
- RESTful API(官方)
- PyMilvus(Python SDK)(官方)
- Go SDK(官方)
- Java SDK(官方)
- Node.js(JavaScript)SDK(官方)
- C#(微软提供)
- C++ SDK(开发中)
- Rust SDK(开发中)
高级数据类型
除了原始数据类型,Milvus 还支持各种高级数据类型及其各自适用的距离度量。
为什么选择 Milvus?
-
高性能和高可用性
Milvus 采用计算与存储分离的分布式架构。Milvus 可以横向扩展并适应多样化的流量模式,通过独立增加读取繁重工作负载的查询节点和写入繁重工作负载的数据节点来实现最佳性能。K8s 上的无状态微服务允许从故障中快速恢复,确保了高可用性。通过在多个查询节点上加载数据段,对复制的支持进一步增强了容错能力和吞吐量。请参见性能比较基准。
-
支持各种向量索引类型和硬件加速
Milvus 分离了系统和核心向量搜索引擎,使其能够支持针对不同场景优化的所有主要向量索引类型,包括 HNSW、IVF、FLAT(暴力)、SCANN 和 DiskANN,以及基于量化的变化和mmap。Milvus 针对元数据过滤和范围搜索等高级功能对向量搜索进行了优化。此外,Milvus 还实现了硬件加速以提高向量搜索性能,并支持 GPU 索引,如英伟达的CAGRA。
-
灵活的多租户和热/冷存储
Milvus 通过在数据库、Collection、分区或分区 Key 层面进行隔离来支持多租户。灵活的策略允许单个集群处理数百到数百万个租户,还能确保优化的搜索性能和灵活的访问控制。Milvus 通过冷/热存储提高了成本效益。经常访问的热数据可以存储在内存或固态硬盘中,以获得更好的性能,而访问量较少的冷数据则保存在速度较慢、成本效益较高的存储设备中。这种机制可以大大降低成本,同时保持关键任务的高性能。
-
用于全文搜索和混合搜索的稀疏向量
除了通过密集向量进行语义搜索外,Milvus 还通过 BM25 以及 SPLADE 和 BGE-M3 等学习型稀疏嵌入原生支持全文搜索。用户可以将稀疏向量和密集向量存储在同一个 Collections 中,并定义函数对多个搜索请求的结果进行 Rerankers。查看混合搜索(语义搜索+全文搜索)示例。
-
数据安全和细粒度访问控制
Milvus 通过实施强制用户认证、TLS 加密和基于角色的访问控制(RBAC)来确保数据安全。用户身份验证可确保只有拥有有效凭证的授权用户才能访问数据库,而 TLS 加密则可确保网络内所有通信的安全。此外,RBAC 允许根据用户的角色为其分配特定权限,从而实现精细的访问控制。这些功能使 Milvus 成为企业应用强大而安全的选择,保护敏感数据免遭未经授权的访问和潜在的破坏。
人工智能集成
- Embeddings 模型集成 Embedding 模型将非结构化数据转换为其在高维数据空间中的数字表示,以便您可以将其存储在 Milvus 中。目前,PyMilvus(Python SDK)集成了多个嵌入模型,因此您可以快速将数据准备成向量嵌入。有关详情,请参阅嵌入概述。
- Reranker 模型集成 在信息检索和生成式人工智能领域,Reranker 是优化初始搜索结果顺序的重要工具。PyMilvus 也集成了几种 Rerankers 模型,以优化初始搜索返回结果的顺序。详情请参考Rerankers 概述。
- LangChain 和其他人工智能工具集成 在 GenAI 时代,LangChain 等工具受到了应用程序开发人员的广泛关注。作为核心组件,Milvus 通常在此类工具中充当向量存储。要了解如何将 Milvus 集成到您喜爱的人工智能工具中,请参阅我们的集成和教程。
工具和生态系统
- Attu Attu 是一个一体化的直观图形用户界面,可帮助您管理 Milvus 及其存储的数据。有关详情,请参阅Attu存储库。
- Birdwatcher Birdwatcher 是 Milvus 的调试工具。使用它连接到 etcd,你可以检查 Milvus 系统的状态,或动态配置它。有关详情,请参阅Birdwatcher。
- Promethus 和 Grafana 集成 Promethus 是 Kubernetes 的开源系统监控和警报工具包。Grafana 是一个开源可视化堆栈,可以连接所有数据源。您可以使用 Promethus 和 Grafana 作为监控服务提供商,对 Milvus Distributed 的性能进行可视化监控。有关详情,请参阅部署监控服务。
- Milvus 备份 Milvus 备份是一个允许用户备份和恢复 Milvus 数据的工具。它同时提供 CLI 和 API,以适应不同的应用场景。详情请参阅Milvus 备份。
- Milvus Capture Data Change (CDC) Milvus-CDC 可以捕获和同步 Milvus 实例中的增量数据,并通过在源实例和目标实例之间的无缝传输,确保业务数据的可靠性,从而轻松实现增量备份和灾难恢复。详情请参阅Milvus CDC。
- Milvus 连接器 Milvus 为您规划了一套连接器,以便将 Milvus 与 Apache Spark 等第三方工具无缝集成。目前,您可以使用我们的 Spark 连接器将 Milvus 数据馈送到 Apache Spark 进行机器学习处理。有关详情,请参阅Spark-Milvus Connector。
- 向量传输服务(VTS) Milvus 为您提供了一套工具,用于在 Milvus 实例和一系列数据源(包括 Zilliz 集群、Elasticsearch、Postgres (PgVector) 和另一个 Milvus 实例)之间传输数据。有关详情,请参阅VTS。